Run Data Feed Forward on a Unified Server#
About this tutorial#
Data Feed Forward(DFF) allows collection of test data from different test stages to be transmitted to other regions or OSAT’s ACS Unified Servers. It also enables retrieval of DFF data across ACS Unified Servers for machine learning to improve production efficiency and quality.
Purpose#
In this tutorial, you will learn how to:
Enable DFF on the Host Controller and run SMT8 test program to trigger DFF data reading and calculation in the DPAT application which is running on Edge within a single AUS environment.
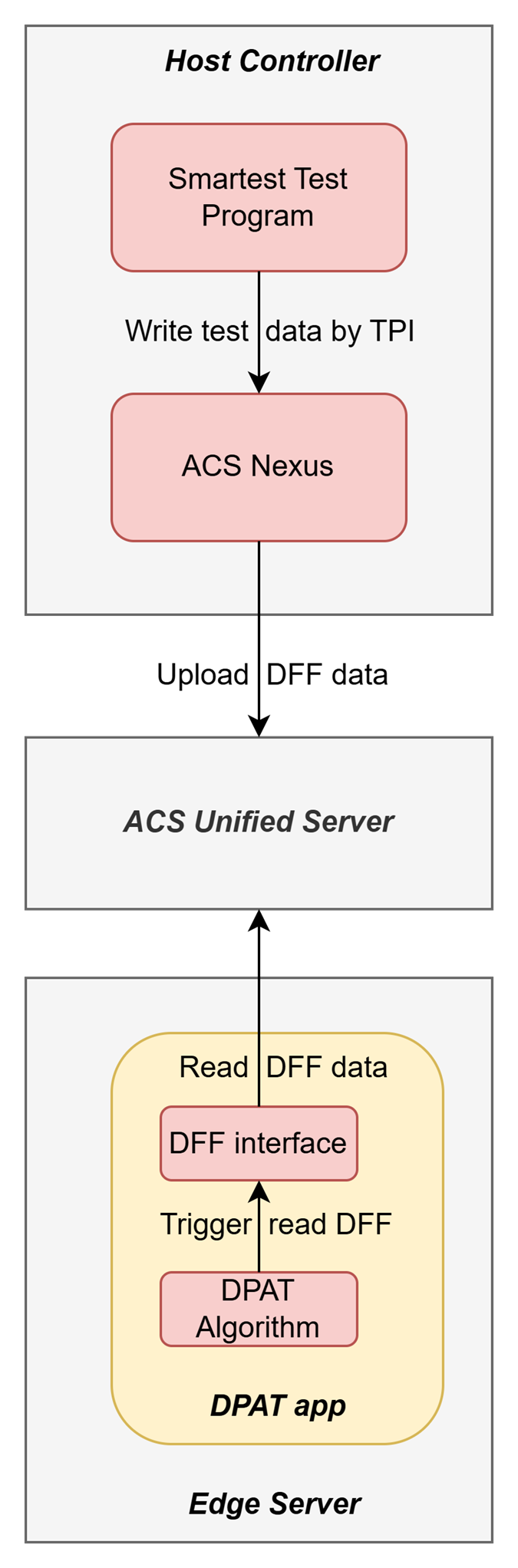
The diagram below illustrates DFF data stream between VMs:
When the test program runs with DFF enabled, Nexus sends DFF data to the Unified Server. On the Edge Server, the DPAT application retrieves this data via the DFF interface. The DFF data is then used in DPAT calculations, resulting in more precise test limits compared to running the test program without DFF. This improvement is due to the inclusion of more data points in the statistical analysis.
Compatibility and Prerequisites#
System Compatibility#
SmarTest 8 / Nexus 3.1.0 / Edge 3.4.0-prod / Unified Server 2.3.0-prod
Prerequisites#
You need to request access to the ACS Container Hub, and create your own user account and project.
Environment Preparation#
Note: The ‘adv-dpat’ project we are using below is for demonstration purposes. You will need to replace it with your own project accordingly.
Create Essential VMs for RTDI#
Click the “Add” button to add VMs:
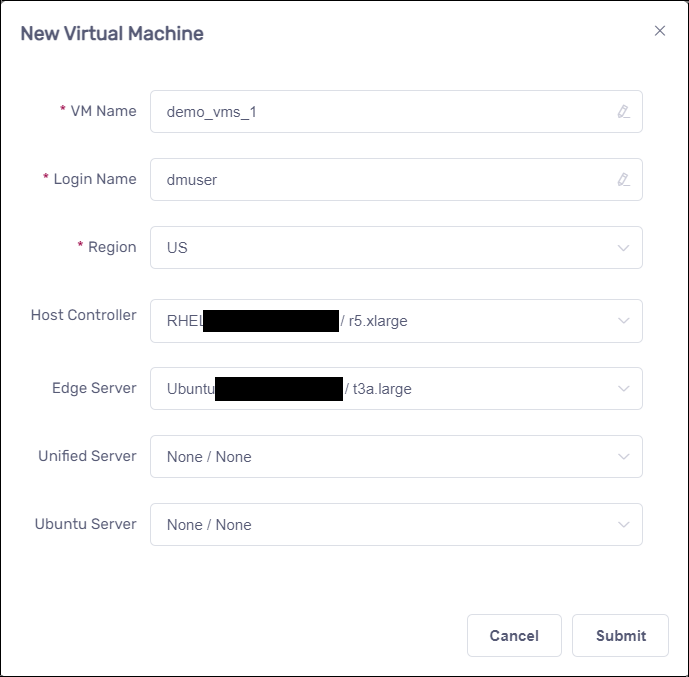
Create Host Controller and Edge Server#
SmarTest test program and Nexus will run on the Host Controller.
The docker image that contains the DPAT app will run on the Edge Server.
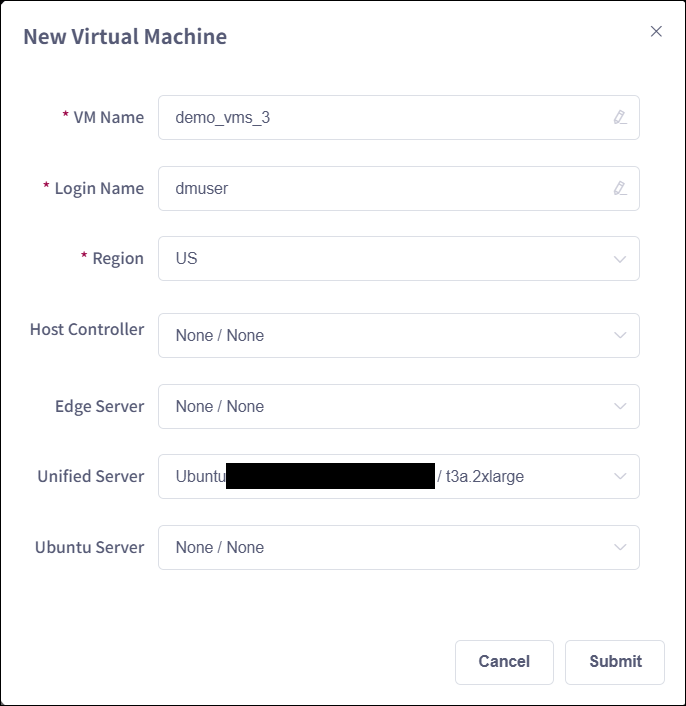
Create Unified Server#
As DFF data landing zone between Nexus and DPAT app
Configure Unified Server and submit DFF configuration request by Feedback#
Config Unified Server by the following.
Submit feedback for DFF configuration.
Click “FEEDBACK” on the right top of “Virtual Machine” page.
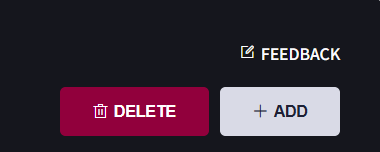
In the popped up “Feedback” dialog
add Summary
DFF configuration request
add Description
Host Controller name: XXXX private IP: XXX.XXX.XXX.XXX Edge Server name: XXXX private IP: XXX.XXX.XXX.XXX Unified Server: name: XXXX private IP: XXX.XXX.XXX.XXX Contact me by: <email address>
Click “Submit”
Application Deployment#
Note: The ‘adv-dpat’ project we are using below is for demonstration purposes. You will need to replace it with your own project accordingly.
Transfer demo program to the Host Controller#
Download the test program
Click to download the application-dpat-v3.1.0-RHEL74.tar.gz archive(a simple DPAT algorithm in Python) to your computer.
Note that: If you are using “RHEL79_ST8.7” VM image for running SMT8, you can download the application-dpat-v3.1.0-RHEL79.tar.gz archive, it contains code enhanced SMT8 test method codes.
Transfer the file to the ~/apps directory on the Host Controller VM
Please refer to the “Transferring files” section of VM Management page.
In the VNC GUI, extract files in the bash console.
For RHEL74:
cd ~/apps/ tar -zxf application-dpat-v3.1.0-RHEL74.tar.gz
For RHEL79:
cd ~/apps/ tar -zxf application-dpat-v3.1.0-RHEL79.tar.gz
Create Docker image for DPAT app#
Login to ACS Container Hub.
sudo docker login registry.advantest.com --username ChangeToUserName --password ChangeToSecret
Set DFF_FLAG=”True” in Dockerfile to enable DFF in DPAT app
Navigate to the DPAT app directory(~/apps/application-dpat-v3.1.0/rd-app_dpat_py), you can find these files
Dockerfile: this is used for building DPAT app docker image
Click to expand!
FROM registry.advantest.com/adv-dpat/python39-basic:2.0 RUN yum install -y openssh-server RUN mkdir /var/run/sshd RUN echo 'root:root123' | chpasswd RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config RUN sed 's@session\s*required\s*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd EXPOSE 22 # set nexus env variables WORKDIR / RUN python3.9 -m pip install pandas jsonschema # copy run files and directories RUN mkdir -p /dpat-app;chmod a+rwx /dpat-app RUN mkdir -p /dpat-app/data;chmod a+rwx /dpat-app/data RUN touch dpat-app/__init__.py COPY workdir /dpat-app/workdir COPY conf /dpat-app/conf # RUN yum -y install libunwind-devel RUN echo 'export $(cat /proc/1/environ |tr "\0" "\n" | xargs)' >> /etc/profile ENV LOG_FILE_PATH "/tmp/app.log" ENV DFF_FLAG="True" WORKDIR /dpat-app/workdir RUN /usr/bin/ssh-keygen -A RUN echo "python3.9 -u /dpat-app/workdir/run_dpat.py&" >> /start.sh RUN echo "/usr/sbin/sshd -D" >> /start.sh CMD sh /start.sh
workdir/run_dpat.py: this is the main entry point for the DPAT app
Click to expand!
""" Copyright 2023 ADVANTEST CORPORATION. All rights reserved Dynamic Part Average Testing This module allows the user to calculate new limits based on dynamic part average testing. It is assumed that this is being run on the docker container with the Nexus connection. """ import json from AdvantestLogging import logger from dpat import DPAT from oneapi import OneAPI, send_command def run(nexus_data, args, save_result_fn): """Callback function that will be called upon receiving data from OneAPI Args: nexus_data: Datalog coming from nexus args: Arguments set by user """ base_limits = args["baseLimits"] dpat = args["DPAT"] # persistent class # compute dpat to get new high/low limits dpat.compute_once(nexus_data, base_limits, logger, args) results_df, new_limits = dpat.datalog() # logger.info(new_limits) if args["VariableControl"] == True: # Send dpat computed data back to Host Controller Nexus, the Smartest will receive the data from Nexus send_command(new_limits, "VariableControl") save_result_fn(results_df) def main(): """Set logger and call OneAPI""" logger.info("Starting DPAT datacolection and computation") logger.info("Copyright 2022 - Advantest America Inc") with open("data/base_limits.json", encoding="utf-8") as json_file: base_limits = json.load(json_file) args = { "DPAT": DPAT(), "baseLimits": base_limits, "config_path": "../conf/test_suites.ini", "setPathStorage": "data", "setPrefixStorage": "Demo_Dpat_123456", "saveStat": True, "VariableControl": False, # Note: smt version is not visible from run_dpat, so it is set in sample.py in consumeLotStart } logger.info("Starting OneAPI") """ Create a OneAPI instance to receive Smartest data from Host Controller Nexus, the callback function "run" will be called when data received with the parameter in the "args" """ oneapi = OneAPI(callback_fn=run, callback_args=args) oneapi.start() if __name__ == "__main__": main()
workdir/dpat.py: this is the core algorithm for DPAT calculation
Click to expand!
""" Copyright 2023 ADVANTEST CORPORATION. All rights reserved This module contains a class and modules that allow the user to calculate new limits based on dynamic part average testing. It is assumed that this is being run on the docker container with the Nexus connection, being called by run_dpat.py. """ import time from typing import Dict, List import numpy as np import pandas as pd class DPAT: """ This class allows the user to calculate new limits based on dynamic part average testing. It is assumed that this is being run on the docker container with the Nexus connection. Contains the following methods: * save_stat(results, df_cumulative_raw, args) * check_new_limits(df_new_limits) * save_stat(results, df_cumulative_raw, args) * stdev_compute(df_cumulative_raw, return_columns) * stdev_full_compute(df_stdev_full, return_columns) * iqr_full_compute(df_iqr_full, return_columns) * iqr_window_compute(df_iqr_full, return_columns) * stdev_compute(df_cumulative_raw, return_columns) * compute(df_base_limits, df_cumulative_raw, args) * datalog(nexus_data, df_base_limits, df_cumulative_raw, args) * run(data, args) * main - the main function of the script """ def __init__(self, ): self.counter = 0 def compute_once(self, nexus_data: str, base_limits: pd.DataFrame, logger, args): """Preprocess data, setting base values and columns. Should run only once. Args: nexus_data: string with pin values coming from nexus base_limits: DataFrame with base limits and parameters args: Dictionary with arguments set on main by user """ self.counter += 1 self.nexus_data = nexus_data self.args = args self.logger = logger self.df_base_limits, self.df_cumulative_raw = self.preprocess_data(base_limits) def save_stat( self, results: pd.DataFrame, df_cumulative_raw: pd.DataFrame, args: Dict ): """Save new limits and raw file into csv. Args: df_base_limits: DataFrame with base limits and parameters df_cumulative_raw: DataFrame with base values and columns args: Dictionary with argsurations parameters set from user """ self.logger.info("=> Start save_stat") set_path_storage = args.get("setPathStorage") set_prefix_storage = args.get("setPrefixStorage") file_to_save_raw = set_path_storage + "/" + set_prefix_storage + "_raw.csv" file_to_save = set_path_storage + "/" + set_prefix_storage + "_stdev.csv" df_cumulative_raw.to_csv(file_to_save_raw, mode="a", index=False) results.to_csv(file_to_save, mode="a", index=False) self.logger.info("=> End save_stat") def check_new_limits(self, df_new_limits: pd.DataFrame) -> List: """Check new limits against existing thresholds and return ids that are off limits. The ids that don't meet the criteria are resetted to base limits. Args: df_new_limits: DataFrame calculated limits Return: test_ids: List with test_ids that are off the base limits """ # New limits that are below user defined threshold below_threshold = df_new_limits[ (df_new_limits["limit_Usl"] - df_new_limits["limit_Lsl"]) < (df_new_limits["PassRangeUsl"] - df_new_limits["PassRangeLsl"]) * df_new_limits["DPAT_Threshold"] ] # New limits that are below base lower limit below_lsl = df_new_limits[ (df_new_limits["N"] < df_new_limits["DPAT_Samples"]) | (df_new_limits["limit_Lsl"] < df_new_limits["PassRangeLsl"]) * df_new_limits["DPAT_Threshold"] ] # New limits that are above base upper limit above_usl = df_new_limits[ (df_new_limits["N"] < df_new_limits["DPAT_Samples"]) | (df_new_limits["limit_Usl"] > df_new_limits["PassRangeUsl"]) * df_new_limits["DPAT_Threshold"] ] test_ids = [] if not above_usl.empty: test_ids = above_usl.TestId.unique().tolist() if not below_lsl.empty: test_ids = test_ids + below_lsl.TestId.unique().tolist() if not below_threshold.empty: test_ids = test_ids + below_threshold.TestId.unique().tolist() return list(set(test_ids)) # return unique testd_ids def stdev_full_compute( self, df_stdev_full: pd.DataFrame, return_columns: List ) -> pd.DataFrame: """Compute stdev method for specific test_ids. It updates the lower and upper limits following this formula: LPL = Mean - <dpat_sigma> * Sigma UPL = Mean + <dpat_sigma> * Sigma, Where <dpat_sigma> is an user defined parameter. Args: df_stdev_full: DataFrame with base values and columns return_columns: Columns to filter returned dataframe on Return: df_result: DataFrame with calculated stdev full and specific return columns """ df_stdev_full.loc[:, 'N'] = \ df_stdev_full.groupby('TestId')['TestId'].transform('count').values df_n = df_stdev_full[df_stdev_full["N"] > 1] df_one = df_stdev_full[df_stdev_full["N"] <= 1] mean = df_n.groupby("TestId")["PinValue"].transform(np.mean) stddev = df_n.groupby("TestId")["PinValue"].transform(lambda x: np.std(x, ddof=1)) # Calculate new limits according to stdev sample df_n.loc[:, "stdev_all"] = stddev.values df_n.loc[:, "limit_Lsl"] = (mean - (stddev * df_n["DPAT_Sigma"])).values df_n.loc[:, "limit_Usl"] = (mean + (stddev * df_n["DPAT_Sigma"])).values # Assign base limits to test_ids with a single instance df_one.loc[:, "limit_Lsl"] = df_one["PassRangeLsl"].values df_one.loc[:, "limit_Usl"] = df_one["PassRangeUsl"].values df_one.loc[:, "stdev_all"] = 0 df_result = pd.concat([df_one, df_n])[return_columns].drop_duplicates() return df_result def stdev_window_compute( self, df_stdev_window: pd.DataFrame, return_columns: List ) -> pd.DataFrame: """Compute stdev method for a specific window of test_ids. The mean and sigma are calculated for that window, and then it updates the lower and upper limits following this formula: LPL = Mean - <dpat_sigma> * Sigma UPL = Mean + <dpat_sigma> * Sigma, Where <dpat_sigma> is an user defined parameter. Args: df_stdev_window: DataFrame with base values and columns return_columns: Columns to filter returned dataframe on Return: df_result: DataFrame with calculated stdev window and specific return columns """ df_stdev_window.loc[:, 'N'] = \ df_stdev_window.groupby('TestId')['TestId'].transform('count').values # Separate test_ids with more than one sample df_n = df_stdev_window[df_stdev_window["N"] > 1] df_one = df_stdev_window[df_stdev_window["N"] <= 1] # Slice df according to window_size df_stdev_window.loc[:, 'N'] = df_stdev_window["DPAT_Window_Size"].values df_window_size = df_n.groupby("TestId").apply( lambda x: x.iloc[int(-x.N.values[0]):] ).reset_index(drop=True) if not df_n.empty: # Calculate new limits mean = df_window_size.groupby("TestId")["PinValue"].transform(np.mean).values stddev = df_window_size.groupby("TestId")["PinValue"].transform( lambda x: np.std(x, ddof=1) ).values df_n.loc[:, "stdev_all"] = stddev df_n.loc[:, "limit_Lsl"] = (mean - (stddev * df_n["DPAT_Sigma"])).values df_n.loc[:, "limit_Usl"] = (mean + (stddev * df_n["DPAT_Sigma"])).values # Assign base limits to test_ids with a single instance df_one.loc[:, "limit_Lsl"] = df_one["PassRangeLsl"].values df_one.loc[:, "limit_Usl"] = df_one["PassRangeUsl"].values df_one.loc[:, "stdev_all"] = 0 df_result = pd.concat([df_n, df_one])[return_columns].drop_duplicates() return df_result def iqr_full_compute( self, df_iqr_full: pd.DataFrame, return_columns: List ) -> pd.DataFrame: """ Update the lower and upper limits following this formula: IQR = Upper Quartile(Q3) - Lower Quartile(Q1) LSL = Q1 - 1.5 IQR USL = Q3 + 1.5 IQR Args: df_iqr_full: DataFrame with base values and columns return_columns: Columns to filter returned dataframe on Return: df_result: DataFrame with calculated IQR full and specific return columns """ window_size = df_iqr_full["DPAT_Window_Size"] df_iqr_full.loc[:, "N"] = window_size df_iqr_full.loc[:, 'N'] = df_iqr_full.groupby('TestId')['TestId'].transform('count') # Separate test_ids with more than one sample df_n = df_iqr_full[df_iqr_full["N"] > 1] df_one = df_iqr_full[df_iqr_full["N"] <= 1] if not df_n.empty: # Compute new limits first_quartile = df_n.groupby("TestId").PinValue.quantile(q=0.25) upper_quartile = df_n.groupby("TestId").PinValue.quantile(q=0.75) iqr = upper_quartile - first_quartile multiple = df_n.groupby("TestId")["DPAT_IQR_Multiple"].first() df_n = df_n[return_columns].drop_duplicates() df_n.loc[:, "limit_Lsl"] = (first_quartile - (multiple * iqr)).values df_n.loc[:, "limit_Usl"] = (upper_quartile + (multiple * iqr)).values df_n.loc[:, "q1_all"] = first_quartile.values df_n.loc[:, "q3_all"] = upper_quartile.values # Assign base limits to test_ids with a single instance df_one.loc[:, "limit_Lsl"] = df_one["PassRangeLsl"].values df_one.loc[:, "limit_Usl"] = df_one["PassRangeUsl"].values df_one.loc[:, "q1_all"] = "N/A" df_one.loc[:, "q3_all"] = "N/A" df_result = pd.concat([df_n, df_one])[return_columns] return df_result def iqr_window_compute( self, df_iqr_window: pd.DataFrame, return_columns: List ) -> pd.DataFrame: """Before calculating the limits, it gets slices the df according to the <window_size>. Then it updates the lower and upper limits following this formula: IQR = Upper Quartile(Q3) - Lower Quartile(Q1) LSL = Q1 - 1.5 IQR USL = Q3 + 1.5 IQR Args: df_iqr_window: DataFrame with base values and columns return_columns: Columns to filter returned dataframe on Return: df_result: DataFrame with calculated IQR window and specific return columns """ window_size = df_iqr_window["DPAT_Window_Size"].values df_iqr_window.loc[:, "window_size"] = window_size df_iqr_window.loc[:, 'N'] = \ df_iqr_window.groupby('TestId')['TestId'].transform('count').values # Separate test_ids with more than one sample df_n = df_iqr_window[df_iqr_window["N"] > 1] df_one = df_iqr_window[df_iqr_window["N"] <= 1] if not df_n.empty: # Slice df according to window_size df_window_size = df_n.groupby("TestId").apply( lambda x: x.iloc[int(-x.window_size.values[0]):] ).reset_index(drop=True) # Calculate IQR first_quartile = df_window_size.groupby(["TestId"]).PinValue.quantile(q=0.25) upper_quartile = df_window_size.groupby(["TestId"]).PinValue.quantile(q=0.75) iqr = upper_quartile - first_quartile multiple = df_n.groupby("TestId")["DPAT_IQR_Multiple"].first() df_n = df_n[return_columns].drop_duplicates() # Calculate new limits df_n.loc[:, "limit_Lsl"] = (first_quartile - (multiple * iqr)).values df_n.loc[:, "limit_Usl"] = (upper_quartile + (multiple * iqr)).values df_n.loc[:, "q1_window"] = first_quartile.values df_n.loc[:, "q3_window"] = upper_quartile.values # Assign base limits to test_ids with a single instance df_one.loc[:, "limit_Lsl"] = df_one["PassRangeLsl"].values df_one.loc[:, "limit_Usl"] = df_one["PassRangeUsl"].values df_one.loc[:, "q1_window"] = "N/A" df_one.loc[:, "q3_window"] = "N/A" df_result = pd.concat([df_n, df_one]) return df_result[return_columns] def stdev_sample_compute( self, df_cumulative_raw: pd.DataFrame, return_columns: List ) -> pd.DataFrame: """ Updates the lower and upper limits following this formula: LSL = Mean - <multiplier> * Sigma USL = Mean + <multiplier> * Sigma Args: df_cumulative_raw: DataFrame with base values and columns return_columns: Columns to filter returned dataframe on Return: df_stdev: DataFrame with calculated stdev and specific return columns """ df_stdev = df_cumulative_raw[ (df_cumulative_raw["DPAT_Type"] == "STDEV") & (df_cumulative_raw["nbr_executions"] > 1) ] df_stdev_one = df_cumulative_raw[ (df_cumulative_raw["DPAT_Type"] == "STDEV") & (df_cumulative_raw["nbr_executions"] <= 1) ] df_stdev.loc[:, "stdev"] = ( ( df_stdev["nbr_executions"] * df_stdev["sum_of_squares"] - df_stdev["sum"] * df_stdev["sum"] ) / ( df_stdev["nbr_executions"] * (df_stdev["nbr_executions"] - 1) ) ).pow(1./2).values mean = ( df_stdev["sum"] / df_stdev["nbr_executions"] ) df_stdev.loc[:, "limit_Lsl"] = (mean - (df_stdev["stdev"] * df_stdev["DPAT_Sigma"])).values df_stdev.loc[:, "limit_Usl"] = (mean + (df_stdev["stdev"] * df_stdev["DPAT_Sigma"])).values df_stdev_one.loc[:, "limit_Lsl"] = df_stdev_one["PassRangeLsl"].values df_stdev_one.loc[:, "limit_Usl"] = df_stdev_one["PassRangeUsl"].values df_stdev = pd.concat([df_stdev, df_stdev_one])[return_columns] return df_stdev def compute( self, df_base_limits: pd.DataFrame, df_cumulative_raw: pd.DataFrame, args: Dict ) -> pd.DataFrame: """Compute new limits with standard deviation and IQR methods Args: df_base_limits: DataFrame with base limits and parameters df_cumulative_raw: DataFrame with base values and columns args: Dictionary with args parameters set from user Returns: new_limits: DataFrame with new limits after compute """ self.logger.info("=>Starting Compute") # define base columns and fill with NANs df_cumulative_raw["stdev_all"] = np.nan df_cumulative_raw["stdev_window"] = np.nan df_cumulative_raw["stdev"] = np.nan df_cumulative_raw["q1_all"] = np.nan df_cumulative_raw["q3_all"] = np.nan df_cumulative_raw["q1_window"] = np.nan df_cumulative_raw["q3_window"] = np.nan df_cumulative_raw["N"] = np.nan df_cumulative_raw["limit_Lsl"] = np.nan df_cumulative_raw["limit_Usl"] = np.nan return_columns = [ "TestId", "stdev_all", "stdev_window", "stdev", "q1_all", "q3_all", "q1_window", "q3_window", "N", "limit_Lsl", "limit_Usl", "PassRangeUsl", "PassRangeLsl" ] in_time = time.time() # Updates the lower and upper limits following this formula: # LSL = Mean - <multiplier> * Sigma (sample) # USL = Mean + <multiplier> * Sigma (sample) df_stdev = self.stdev_sample_compute(df_cumulative_raw, return_columns) # Updates the lower and upper limits according to sigma and mean df_stdev_full = df_cumulative_raw[df_cumulative_raw["DPAT_Type"] == "STDEV_FULL"] df_stdev_full = self.stdev_full_compute(df_stdev_full, return_columns) # Updates limits after getting a sample of <window_size>. df_stdev_window = df_cumulative_raw[ df_cumulative_raw["DPAT_Type"] == "STDEV_RUNNING_WINDOW" ] df_stdev_window = self.stdev_window_compute(df_stdev_window, return_columns) # Calculates limits based on Interquartile range. # IQR = Upper Quartile(Q3) - Lower Quartile(Q1) # LSL = Q1 - 1.5 IQR # USL = Q3 + 1.5 IQR df_iqr_full = df_cumulative_raw[df_cumulative_raw["DPAT_Type"] == "IQR_FULL"] df_iqr_full = self.iqr_full_compute(df_iqr_full, return_columns) # Gets a sample of the dataframe of <window_size> and then uses IQR df_iqr_window = df_cumulative_raw[df_cumulative_raw["DPAT_Type"] == "IQR_RUNNING_WINDOW"] df_iqr_window = self.iqr_window_compute(df_iqr_window, return_columns) # Concatenates the 5 methods in one dataframe new_limits_df = pd.concat( [df_stdev, df_stdev_full, df_stdev_window, df_iqr_full, df_iqr_window] ).sort_values(by = "TestId").reset_index(drop=True) # Check for test_ids that don't meet the criteria and are off limits test_ids_off_limits = self.check_new_limits(new_limits_df.merge(df_base_limits)) if len(test_ids_off_limits) > 0: # Sets the off limits ids to the base values new_limits_df.loc[new_limits_df.TestId.isin(test_ids_off_limits), "limit_Usl"] = \ new_limits_df["PassRangeUsl"] new_limits_df.loc[new_limits_df.TestId.isin(test_ids_off_limits), "limit_Lsl"] = \ new_limits_df["PassRangeLsl"] new_limits_df["PassRangeLsl"] = new_limits_df["limit_Lsl"] new_limits_df["PassRangeUsl"] = new_limits_df["limit_Usl"] # Prepare dataframe with return format new_limits_df = new_limits_df.merge( df_cumulative_raw[["TestId", "TestSuiteName", "Testname", "pins"]].drop_duplicates(), on = "TestId", how="left" ) print(new_limits_df) # Pick return columns and drop duplicates new_limits_df = new_limits_df[[ "TestId", "TestSuiteName", "Testname", "pins", "PassRangeLsl", "PassRangeUsl", ]].drop_duplicates() out_time = time.time() self.logger.info("Compute Setup Test Time=%.3f} sec" % (out_time - in_time)) # Parameter set by user, persists result in a file if args.get("saveStat"): self.save_stat( new_limits_df, df_cumulative_raw, args ) self.logger.info("=> End Compute") return new_limits_df def format_result(self, result_df: pd.DataFrame) -> str: """Convert dataframe to string with variables to be used in VariableControl Follows this format: TESTID0,value TESTID1,value TESTID2,value """ new_limits_df = result_df.copy() new_limits_df.sort_values(by="TestId").reset_index(drop=True, inplace=True) new_limits_df["test_id_var"] = "TestId" + new_limits_df.index.astype(str) + "," + \ new_limits_df["TestId"].astype(str) test_ids = ' '.join(new_limits_df["test_id_var"]) new_limits_df["limits_lsl"] = "limit_lsl." + new_limits_df["TestId"].astype(str) + \ "," + new_limits_df["PassRangeLsl"].astype(str) new_limits_df["limits_usl"] = "limit_usl." + new_limits_df["TestId"].astype(str) + \ "," + new_limits_df["PassRangeUsl"].astype(str) limits_lsl = ' '.join(new_limits_df["limits_lsl"]) limits_usl = ' '.join(new_limits_df["limits_usl"]) variable_command = limits_lsl + " " + test_ids + " " + limits_lsl + " " + limits_usl return variable_command def datalog(self,) -> str: """Prepare data and compute new limits Returns: variable_command: formatted command with new_limits after compute """ nexus_data = self.nexus_data df_base_limits = self.df_base_limits df_cumulative_raw = self.df_cumulative_raw args = self.args self.logger.info("=> Starting Datalog") start = time.time() # Read string from nexus. Note that this does not read a csv file. current_result_datalog = nexus_data # Prepare base values and columns df_cumulative_raw = df_cumulative_raw[["TestId", "sum", "sum_of_squares", "nbr_executions"]] df_cumulative_raw = df_cumulative_raw.merge(current_result_datalog, on="TestId") df_cumulative_raw["nbr_executions"] = df_cumulative_raw["nbr_executions"] + 1 df_cumulative_raw["sum"] = df_cumulative_raw["sum"] + df_cumulative_raw["PinValue"] df_cumulative_raw["sum_of_squares"] = ( df_cumulative_raw["sum_of_squares"] + df_cumulative_raw["PinValue"] * df_cumulative_raw["PinValue"] ) df_cumulative_raw = df_cumulative_raw.merge( df_base_limits, on="TestId", how="left" ) # Compute new limits according to stdev and IQR methods new_limits_df = self.compute( df_base_limits, df_cumulative_raw, args ) end = time.time() self.logger.info( "Total Setup/Parallel Computation and Return result Test Time=%f" % (end-start) ) self.logger.info("=> End of Datalog:") # Format the result in Nexus Variable format return new_limits_df.copy(), self.format_result(new_limits_df) def preprocess_data(self, base_limits: pd.DataFrame) -> pd.DataFrame: """Initialize dataframes with base values before they can be computed Args: base_limits: Dict that contains base limits and parameters, extracted from json file Returns: df_base_limits: DataFrame with base_limits and parameters cumulative_statistics: DataFrame with base columns and values to be used in compute """ self.logger.info("=>Beginning of Init") df_base_limits = pd.DataFrame.from_dict(base_limits, orient="index") df_base_limits["TestId"] = df_base_limits.index.astype(int) df_base_limits.reset_index(inplace=True, drop=True) # Pick only columns of interest cumulative_statistics = df_base_limits[ ["TestId", "PassRangeUsl", "PassRangeLsl", "DPAT_Sigma"] ].copy() # Set 0 to base columns cumulative_statistics["nbr_executions"] = 0 cumulative_statistics["sum_of_squares"] = 0 cumulative_statistics["sum"] = 0 self.logger.info("=>End of Init") return df_base_limits, cumulative_statistics
workdir/oneapi.py:
By using OneAPI, this code performs the following functions:
Retrieves test data from the Host Controller and sends it to the DPAT algorithm.
Receives the DPAT results from the algorithm and sends them back to the Host Controller.
Click to expand!
from liboneAPI import Interface from liboneAPI import AppInfo from sample import SampleMonitor from sample import sendCommand import signal import sys import pandas as pd from AdvantestLogging import logger def send_command(result_str, command): # name = command; # param = "DriverEvent LotStart" # sendCommand(name, param) name = command param = "DriverEvent LotStart" sendCommand(name, param) name = command param = "Config Enabled=1 Timeout=10" sendCommand(name, param) name = command param = "Set " + result_str sendCommand(name, param) logger.info(result_str) class OneAPI: def __init__(self, callback_fn, callback_args): self.callback_args = callback_args self.get_suite_config(callback_args["config_path"]) self.monitor = SampleMonitor( callback_fn=callback_fn, callback_args=self.callback_args ) def get_suite_config(self, config_path): # conf/test_suites.ini test_suites = [] with open(config_path) as f: for line in f: li = line.strip() if not li.startswith("#"): test_suites.append(li.split(",")) self.callback_args["test_suites"] = pd.DataFrame( test_suites, columns=["testNumber", "testName"] ) def start( self, ): signal.signal(signal.SIGINT, quit) logger.info("Press 'Ctrl + C' to exit") me = AppInfo() me.name = "sample" me.vendor = "adv" me.version = "2.1.0" Interface.registerMonitor(self.monitor) NexusDataEnabled = True # whether to enable Nexus Data Streaming and Control TPServiceEnabled = ( True # whether to enable TPService for communication with NexusTPI ) res = Interface.connect(me, NexusDataEnabled, TPServiceEnabled) if res != 0: logger.info(f"Connect fail. code = {res}") sys.exit() logger.info("Connect succeed.") signal.signal(signal.SIGINT, quit) while True: signal.pause() def quit( self, ): res = Interface.disconnect() if res != 0: logger.info(f"Disconnect fail. code = {res}") sys.exit()
workdir/sample.py: on the method consumeParametricTest(), it will query DFF data from the Unified Server, then use it in the subsequent calculation.
Click to expand!
from liboneAPI import Monitor from liboneAPI import DataType from liboneAPI import TestCell from liboneAPI import Command from liboneAPI import Interface from liboneAPI import toHead from liboneAPI import toSite from liboneAPI import DFFData from liboneAPI import QueryResponse from AdvantestLogging import logger import os import sys import pandas as pd import json import re import threading import time def dff_query(condition: str) -> dict: dffData = {} query_res = QueryResponse() query_res = DFFData.createRawQueryRequest(condition) if query_res.code == DFFData.SUCCEED: jobID = query_res.result if query_res.code == DFFData.COMMON_ERROR: return dffData # error handling: response.errmsg while True: query_res = DFFData.getQueryTaskStatus(jobID) if query_res.code != DFFData.SUCCEED: return dffData # error handling: response.errmsg if query_res.result == "RUNNING": pass # need sleep a while then continue if query_res.result == "COMPLETED": query_res = DFFData.getQueryResult(jobID, "json") if query_res.code != DFFData.SUCCEED: pass # error handling: response.errmsg else : dffData = query_res.result break return dffData def sendCommand(cmd_name, cmd_param): logger.info(f"Command -- send {cmd_name}") tc = TestCell() cmd = Command() cmd.param = cmd_param cmd.name = cmd_name cmd.reason = f"test {cmd.name} command" res = Interface.sendCommand(tc, cmd) if res != 0: logger.info("Send command fail. code = ") class SampleMonitor(Monitor): def __init__(self, callback_fn, callback_args): Monitor.__init__(self) self.mTouchdownCnt = 0 self.result_test_suite = [] self.results_df = pd.DataFrame() self.callback_fn = callback_fn self.callback_args = callback_args self.callback_thread = None # To keep track of the thread self.test_suites = callback_args["test_suites"] self.ecid = None self.time_nanosec = 0 self.stime_nanosec = 0 self.ratime_nanosec = 0 self.atime_nanosec = 0 self.dff_flag = os.environ.get("DFF_FLAG", "false").lower() in ('true', 't') self.dff_dict = {} self.dff_skip_ls = [] def consumeLotStart(self, data): logger.info(sys._getframe().f_code.co_name) self.mTouchdownCnt = 0 # Get SmarTest version smt_ver_info = data.get_TesterosVersion() print("VERSION:" + str(data.get_TesterosVersion())) self._smt_os_version = re.search(r"\d+", smt_ver_info).group() print("VERSION:" + self._smt_os_version) if self._smt_os_version == "8": # for smarTest8 self.callback_args["VariableControl"] = False elif self._smt_os_version == "7": self.callback_args["VariableControl"] = True self.lot_id = data.get_LotId() # logger.info(f"get_Timezone = {data.get_Timezone()}") # logger.info(f"get_SetupTime = {data.get_SetupTime()}") logger.debug(f"get_TimeStamp = {data.get_TimeStamp()}") # logger.info(f"get_StationNumber = {data.get_StationNumber()}") # logger.info(f"get_ModeCode = {data.get_ModeCode()}") # logger.info(f"get_RetestCode = {data.get_RetestCode()}") # logger.info(f"get_ProtectionCode = {data.get_ProtectionCode()}") # logger.info(f"get_BurnTimeMinutes = {data.get_BurnTimeMinutes()}") # logger.info(f"get_CommandCode = {data.get_CommandCode()}") logger.info(f"get_LotId = {data.get_LotId()}") # logger.info(f"get_PartType = {data.get_PartType()}") # logger.info(f"get_NodeName = {data.get_NodeName()}") # logger.info(f"get_TesterType = {data.get_TesterType()}") # logger.info(f"get_JobName = {data.get_JobName()}") # logger.info(f"get_JobRevision = {data.get_JobRevision()}") # logger.info(f"get_SublotId = {data.get_SublotId()}") # logger.info(f"get_OperatorName = {data.get_OperatorName()}") # logger.info(f"get_TesterosType = {data.get_TesterosType()}") # logger.info(f"get_TesterosVersion = {data.get_TesterosVersion()}") # logger.info(f"get_TestType = {data.get_TestType()}") # logger.info(f"get_TestStepCode = {data.get_TestStepCode()}") # logger.info(f"get_TestTemperature = {data.get_TestTemperature()}") # logger.info(f"get_UserText = {data.get_UserText()}") # logger.info(f"get_AuxiliaryFile = {data.get_AuxiliaryFile()}") # logger.info(f"get_PackageType = {data.get_PackageType()}") # logger.info(f"get_FamilyId = {data.get_FamilyId()}") # logger.info(f"get_DateCode = {data.get_DateCode()}") # logger.info(f"get_FacilityId = {data.get_FacilityId()}") # logger.info(f"get_FloorId = {data.get_FloorId()}") # logger.info(f"get_ProcessId = {data.get_ProcessId()}") # logger.info(f"get_OperationFreq = {data.get_OperationFreq()}") # logger.info(f"get_SpecName = {data.get_SpecName()}") # logger.info(f"get_SpecVersion = {data.get_SpecVersion()}") # logger.info(f"get_FlowId = {data.get_FlowId()}") # logger.info(f"get_SetupId = {data.get_SetupId()}") # logger.info(f"get_DesignRevision = {data.get_DesignRevision()}") # logger.info(f"get_EngineeringLotId = {data.get_EngineeringLotId()}") # logger.info(f"get_RomCode = {data.get_RomCode()}") # logger.info(f"get_SerialNumber = {data.get_SerialNumber()}") # logger.info(f"get_SupervisorName = {data.get_SupervisorName()}") # logger.info(f"get_HeadNumber = {data.get_HeadNumber()}") # logger.info(f"get_SiteGroupNumber = {data.get_SiteGroupNumber()}") # headsiteList = data.get_TotalHeadSiteList() # logger.info("get_TotalHeadSiteList:", end="") # for headsite in headsiteList: # logger.info(f" {headsite}", end="") # logger.info("") # logger.info(f"get_ProberHandlerType = {data.get_ProberHandlerType()}") # logger.info(f"get_ProberHandlerId = {data.get_ProberHandlerId()}") # logger.info(f"get_ProbecardType = {data.get_ProbecardType()}") # logger.info(f"get_ProbecardId = {data.get_ProbecardId()}") # logger.info(f"get_LoadboardType = {data.get_LoadboardType()}") # logger.info(f"get_LoadboardId = {data.get_LoadboardId()}") # logger.info(f"get_DibType = {data.get_DibType()}") # logger.info(f"get_DibId = {data.get_DibId()}") # logger.info(f"get_CableType = {data.get_CableType()}") # logger.info(f"get_CableId = {data.get_CableId()}") # logger.info(f"get_ContactorType = {data.get_ContactorType()}") # logger.info(f"get_ContactorId = {data.get_ContactorId()}") # logger.info(f"get_LaserType = {data.get_LaserType()}") # logger.info(f"get_LaserId = {data.get_LaserId()}") # logger.info(f"get_ExtraEquipType = {data.get_ExtraEquipType()}") # logger.info(f"get_ExtraEquipId = {data.get_ExtraEquipId()}") def consumeLotEnd(self, data): logger.info(sys._getframe().f_code.co_name) self.mTouchdownCnt = 0 logger.debug(f"get_TimeStamp = {data.get_TimeStamp()}") # logger.info(f"get_DisPositionCode = {data.get_DisPositionCode()}") # logger.info(f"get_UserDescription = {data.get_UserDescription()}") # logger.info(f"get_ExecDescription = {data.get_ExecDescription()}") def consumeWaferStart(self, data): logger.info(sys._getframe().f_code.co_name) self.mTouchdownCnt = 0 self.dff_dict = {} self.dff_skip_ls = [] logger.debug(f"get_TimeStamp = {data.get_TimeStamp()}") # logger.info(f"get_WaferSize = {data.get_WaferSize()}") # logger.info(f"get_DieHeight = {data.get_DieHeight()}") # logger.info(f"get_DieWidth = {data.get_DieWidth()}") # logger.info(f"get_WaferUnits = {data.get_WaferUnits()}") # logger.info(f"get_WaferFlat = {data.get_WaferFlat()}") # logger.info(f"get_CenterX = {data.get_CenterX()}") # logger.info(f"get_CenterY = {data.get_CenterY()}") # logger.info(f"get_PositiveX = {data.get_PositiveX()}") # logger.info(f"get_PositiveY = {data.get_PositiveY()}") # logger.info(f"get_HeadNumber = {data.get_HeadNumber()}") # logger.info(f"get_SiteGroupNumber = {data.get_SiteGroupNumber()}") # logger.info(f"get_WaferId = {data.get_WaferId()}") def consumeWaferEnd(self, data): logger.info(sys._getframe().f_code.co_name) self.mTouchdownCnt = 0 logger.debug(f"get_TimeStamp = {data.get_TimeStamp()}") # logger.info(f"get_HeadNumber = {data.get_HeadNumber()}") # logger.info(f"get_SiteGroupNumber = {data.get_SiteGroupNumber()}") # logger.info(f"get_TestedCount = {data.get_TestedCount()}") # logger.info(f"get_RetestedCount = {data.get_RetestedCount()}") # logger.info(f"get_GoodCount = {data.get_GoodCount()}") # logger.info(f"get_WaferId = {data.get_WaferId()}") # logger.info(f"get_UserDescription = {data.get_UserDescription()}") # logger.info(f"get_ExecDescription = {data.get_ExecDescription()}") def consumeTestStart(self, data): logger.info(sys._getframe().f_code.co_name) logger.debug(f"get_TimeStamp = {data.get_TimeStamp()}") # headsiteList = data.get_HeadSiteList() # logger.info("get_HeadSiteList:", end="") # for headsite in headsiteList: # logger.info(f" {liboneAPI.toHead(headsite)}|{liboneAPI.toSite(headsite)}", end="") # logger.info("") def consumeTestEnd(self, data): logger.info(sys._getframe().f_code.co_name) self.mTouchdownCnt += 1 logger.debug(f"get_TimeStamp = {data.get_TimeStamp()}") # cnt = data.get_ResultCount() # logger.info(f"get_ResultCount = {cnt}") # for index in range(0, cnt): # tempU32 = data.query_HeadSite(index) # logger.info(f"Head = {liboneAPI.toHead(tempU32)} Site = {liboneAPI.toSite(tempU32)}") # logger.info(f"query_PartFlag = {data.query_PartFlag(index)}") # logger.info(f"query_NumOfTest = {data.query_NumOfTest(index)}") # logger.info(f"query_SBinResult = {data.query_SBinResult(index)}") # logger.info(f"query_HBinResult = {data.query_HBinResult(index)}") # logger.info(f"query_XCoord = {data.query_XCoord(index)}") # logger.info(f"query_YCoord = {data.query_YCoord(index)}") # logger.info(f"query_TestTime = {data.query_TestTime(index)}") # logger.info(f"query_PartId = {data.query_PartId(index)}") # logger.info(f"query_PartText = {data.query_PartText(index)}") def consumeTestFlowStart(self, data): logger.info(sys._getframe().f_code.co_name) logger.debug(f"get_TimeStamp = {data.get_TimeStamp()}") # logger.info(f"get_TestFlowName = {data.get_TestFlowName()}") def consumeTestFlowEnd(self, data): logger.info(sys._getframe().f_code.co_name) logger.debug(f"get_TimeStamp = {data.get_TimeStamp()}") # logger.info(f"get_TestFlowName = {data.get_TestFlowName()}") def consumeParametricTest(self, data): logger.info(sys._getframe().f_code.co_name) cnt = data.get_ResultCount() # logger.info(f"get_ResultCount = {cnt}") for index in range(0, cnt): tempU32 = data.query_HeadSite(index) # logger.info(f"Head = {toHead(tempU32)} Site = {toSite(tempU32)}") # logger.info(f"query_TestNumber = {data.query_TestNumber(index)}") # logger.info(f"query_TestText = {data.query_TestText(index)}") # logger.info(f"query_LowLimit = {data.query_LowLimit(index)}") # logger.info(f"query_HighLimit = {data.query_HighLimit(index)}") # logger.info(f"query_Unit = {data.query_Unit(index)}") # logger.info(f"query_TestFlag = {data.query_TestFlag(index)}") # logger.info(f"query_Result = {data.query_Result(index)}") test_num = data.query_TestNumber(index) if self._smt_os_version == "8": # for smarTest8 test_name = data.query_TestSuite(index) else: test_name = data.query_TestText(index).split(":")[0] result = data.query_Result(index) row = [test_num, test_name, result] # use only specific test_names and test_numbers define in config file # if test_num in set(self.test_suites.testNumber) or test_name in set(self.test_suites.testName): self.result_test_suite.append(row) if self.result_test_suite: # set result test suite as a dataframe test_suite_df = pd.DataFrame(self.result_test_suite, columns=["TestId", "testName", "PinValue"]) # get previous lots data to calculate limit if self.dff_flag and test_num not in self.dff_skip_ls: DPAT_Samples = 5 # default value # get DPAT Sample from base limit if it exists try: if test_name in self.callback_args["baseLimits"].keys(): DPAT_Samples = int(self.callback_args["baseLimits"][test_name]["DPAT_Samples"]) except Exception as e: logger.error(f"Cannot retrieve the DPAT_Samples of {test_name}, {e}") # get previous data using DFF if n_sample is less than DPAT Sample if (test_suite_df["TestId"] == test_num).sum() < DPAT_Samples: # retrieve previous data if it hasn't been fetched before if test_num not in self.dff_dict.keys(): dff_data_ls:list = self.consumeDFFData(test_num) self.dff_dict[test_num] = dff_data_ls dff_data:list = self.dff_dict[test_num] # concatenate previous data to test_suite_df if data is not empty if dff_data: # skip the test number if dff data has already been retrieved self.dff_skip_ls.append(test_num) # append the previous data to result test suite for result in dff_data: self.result_test_suite.append([test_num, test_name, result]) # concatenate previous data df = pd.DataFrame({ "TestId": [test_num] * len(dff_data), "testName": [test_name] * len(dff_data), "PinValue": dff_data }) test_suite_df = pd.concat([test_suite_df, df], axis=0) # execute DPAT using test_suite_df self.callback_thread = self.threaded_callback( self.callback_fn, test_suite_df, self.callback_args ) def consumeFunctionalTest(self, data): logger.info(sys._getframe().f_code.co_name) # cnt = data.get_ResultCount() # logger.info(f"get_ResultCount = {cnt}") # for index in range(0, cnt): # tempU32 = data.query_HeadSite(index) # logger.info(f"Head = {liboneAPI.toHead(tempU32)} Site = {liboneAPI.toSite(tempU32)}") # logger.info(f"query_TestNumber = {data.query_TestNumber(index)}") # logger.info(f"query_TestText = {data.query_TestText(index)}") # logger.info(f"query_TestFlag = {data.query_TestFlag(index)}") # logger.info(f"query_CycleCount = {data.query_CycleCount(index)}") # logger.info(f"query_NumberFail = {data.query_NumberFail(index)}") # failpins = data.query_FailPins(index) # logger.info("query_FailPins:", end="") # for p in failpins: # logger.info(f" {p}", end="") # logger.info("") # logger.info(f"query_VectNam = {data.query_VectNam(index)}") def consumeMultiParametric(self, data): logger.info(sys._getframe().f_code.co_name) # cnt = data.get_ResultCount() # logger.info(f"get_ResultCount = {cnt}") # for index in range(0, cnt): # tempU32 = data.query_HeadSite(index) # logger.info(f"Head = {liboneAPI.toHead(tempU32)} Site = {liboneAPI.toSite(tempU32)}") # logger.info(f"query_TestNumber = {data.query_TestNumber(index)}") # logger.info(f"query_TestText = {data.query_TestText(index)}") # logger.info(f"query_LowLimit = {data.query_LowLimit(index)}") # logger.info(f"query_HighLimit = {data.query_HighLimit(index)}") # logger.info(f"query_Unit = {data.query_Unit(index)}") # logger.info(f"query_TestFlag = {data.query_TestFlag(index)}") # results = data.query_Results(index) # logger.info(f"query_Results: Cnt({len(results)})", end="") # for r in results: # logger.info(f" {r}", end="") # logger.info("") def consumeDeviceData(self, data): logger.info(sys._getframe().f_code.co_name) # logger.info(f"get_TestProgramDir = {data.get_TestProgramDir()}") # logger.info(f"get_TestProgramName = {data.get_TestProgramName()}") # logger.info(f"get_TestProgramPath = {data.get_TestProgramPath()}") # logger.info(f"get_PinConfig = {data.get_PinConfig()}") # logger.info(f"get_ChannelAttribute = {data.get_ChannelAttribute()}") # cnt = data.get_BinInfoCount() # logger.info(f"get_BinInfoCount = {cnt}") # for index in range(0, cnt): # logger.info(f"SBin({data.query_SBinNumber(index)})", end="") # logger.info(f" Name({data.query_SBinName(index)})", end="") # logger.info(f" Type({data.query_SBinType(index)})", end="") # logger.info(f" HBin({data.query_HBinNumber(index)})", end="") # logger.info(f" Name({data.query_HBinName(index)})", end="") # logger.info(f" Type({data.query_HBinType(index)})", end="") # logger.info("") def consumeUserDefinedData(self, data): logger.info(sys._getframe().f_code.co_name) # userDefined = data.get_UserDefined() # for key,value in userDefined.items(): # logger.info(f"[{key}] = {value}") def consumeFile(self, data): logger.info(sys._getframe().f_code.co_name) # logger.info(f"get_FileName = {data.get_FileName()}") def consumeDatalogText(self, data): logger.info(sys._getframe().f_code.co_name) logger.debug(f"get_TimeStamp = {data.get_TimeStamp()}") # logger.info(f"get_DataLogText = {data.get_DataLogText()}") def consumeDFFData(self, test_number: str) -> list: result:list = [] sql_query:str = f""" SELECT lot_id, x_coord, y_coord, p.result, p.low_limit, p.high_limit FROM rtdi_table t LATERAL VIEW explode(t.ptr) as p WHERE p.test_number = {test_number} AND lot_id= '{self.lot_id}' """ dff_data:dict = dff_query(sql_query) # get previous result data if it's not empty if dff_data: parsed_data:dict = json.loads(dff_data) result:list = pd.DataFrame(parsed_data)["result"].tolist() logger.info(f"Retrieve previous data from DFF, data = {result}") else: logger.info("There is no previous data available from DFF") logger.debug(f"The query is '{sql_query}'") return result def consumeData(self, tc, data): try: datatype = data.getType() if datatype == DataType.DATA_TYP_PRODUCTION_LOTSTART: self.consumeLotStart(data) elif datatype == DataType.DATA_TYP_PRODUCTION_LOTEND: if self.callback_thread: self.callback_thread.join() # Wait for the callback thread to finish self.consumeLotEnd(data) elif datatype == DataType.DATA_TYP_PRODUCTION_WAFERSTART: self.consumeWaferStart(data) elif datatype == DataType.DATA_TYP_PRODUCTION_WAFEREND: self.consumeWaferEnd(data) elif datatype == DataType.DATA_TYP_PRODUCTION_TESTSTART: self.consumeTestStart(data) elif datatype == DataType.DATA_TYP_PRODUCTION_TESTEND: self.consumeTestEnd(data) elif datatype == DataType.DATA_TYP_PRODUCTION_TESTFLOWSTART: self.consumeTestFlowStart(data) elif datatype == DataType.DATA_TYP_PRODUCTION_TESTFLOWEND: self.consumeTestFlowEnd(data) elif datatype == DataType.DATA_TYP_MEASURED_PARAMETRIC: self.consumeParametricTest(data) elif datatype == DataType.DATA_TYP_MEASURED_FUNCTIONAL: self.consumeFunctionalTest(data) elif datatype == DataType.DATA_TYP_MEASURED_MULTI_PARAM: self.consumeMultiParametric(data) elif datatype == DataType.DATA_TYP_DEVICE: self.consumeDeviceData(data) elif datatype == DataType.DATA_TYP_USERDEFINED: self.consumeUserDefinedData(data) elif datatype == DataType.DATA_TYP_FILE: self.consumeFile(data) elif datatype == DataType.DATA_TYP_DATALOGTEXT: self.consumeDatalogText(data) else: logger.error(f"Unknown data type: {datatype.name}, data number: {datatype.value}") except Exception as e: logger.error(f"Something went wrong while executing the data handler, dataType = {datatype.name}", exc_info=True) logger.error(f"Error message: {e}") def consumeTPSend(self, tc, data): self.time_nanosec = time.time_ns() logger.info(f"Received data from {tc.testerId}, length is {len(data)} ") logger.info(f"Received data from {tc.testerId}, string is {data} ") lastdata = data datastr = str(data) if "SKU_NAME" in data: jsonObj = json.loads(datastr) logger.info(datastr) for key in jsonObj: logger.debug(key, " : ", jsonObj[key]) logger.debug(f"TPRequest: dataval= {jsonObj[key]}") dataval = jsonObj[key] for subkey in dataval: logger.debug(f"subkey= {subkey}") logger.debug(f"subval= {jsonObj[key][subkey]}") self.ecid = jsonObj["SKU_NAME"]["MSFT_ECID"] logger.info(f"TPSend: {self.ecid=}") self.testname = jsonObj["SKU_NAME"]["testname"] logger.info(f"TPSend: {self.testname=}") # print("TPSend: hosttime= ",hosttime) packetstr = jsonObj["SKU_NAME"]["packetString"] logger.info(f"TPSend: {packetstr=}") rawvalue = jsonObj["SKU_NAME"]["RawValue"] logger.info(f"TPSend: {rawvalue=}") lolim = jsonObj["SKU_NAME"]["LowLim"] logger.info(f"TPSend: {lolim=}") hilim = jsonObj["SKU_NAME"]["HighLim"] logger.info(f"TPSend: {hilim=}") self.stime_nanosec = time.time_ns() return def consumeTPRequest(self, tc, request): logger.info(f"consumeTPRequest Start") logger.info(f"Received request from {tc.testerId}, command is {request}") # Parse the JSON request jsonObj = json.loads(request) action = jsonObj.get("request") # Initialize variables with example values (replace with actual values as needed) adjHBin = -1 self.ratime_nanosec = time.time_ns() if action == "health": print("TPRqst: processing health") response = "success" elif action == "CalcNewLimits" and self.ecid and "PassRangeLsl" in self.results_df: # Construct the dictionary with all the fields edge_min_value = self.results_df["PassRangeLsl"].iloc[-1] edge_max_value = self.results_df["PassRangeUsl"].iloc[-1] selfatime_nanosec = time.time_ns() response_dict = { "MSFT_ECID": self.ecid, "testname": self.testname, "AdjLoLim": str(edge_min_value), "AdjHiLim": str(edge_max_value), "AdjHBin": str(adjHBin), "SendAppTime": str(self.time_nanosec), "SendAppRetTime": str(self.stime_nanosec), "RqstAppTime": str(self.ratime_nanosec), "RqstAppRetTime": str(self.atime_nanosec), } # TODO: Clarify what each of these time requests mean. # Convert the dictionary to a JSON string using json.dumps response = json.dumps(response_dict) else: response = json.dumps({"response": "empty or unsupported action"}) logger.info(f"Response: {response}") return response def threaded_callback(self, callback_fn, dataframe, callback_args): thread = threading.Thread( target=callback_fn, args=(dataframe, callback_args, self.save_result) ) thread.start() return thread def save_result(self, df): self.results_df = df
Build image
cd ~/apps/application-dpat-v3.1.0/rd-app_dpat_py sudo docker build ./ --tag=registry.advantest.com/adv-dpat/adv-dpat-v1:ExampleTag
Push image
sudo docker push registry.advantest.com/adv-dpat/adv-dpat-v1:ExampleTag
You can see that the docker image has been uploaded on the Container Hub.
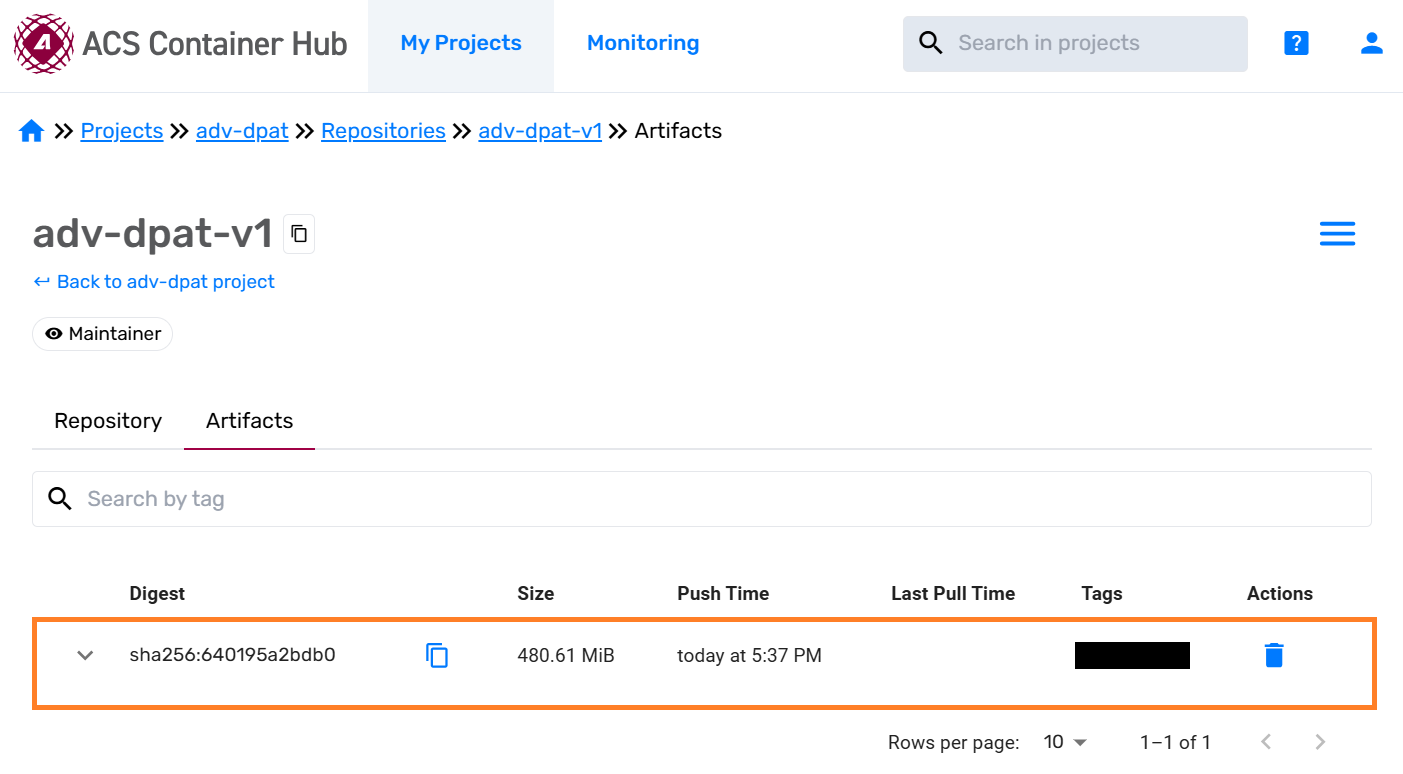
Configure acs_nexus service#
Create /opt/acs/nexus/conf/images.json
{ "selector": { "device_name": "demoRTDI" }, "edge": { "address": "ChangeToEdgeIp", "registry": { "address": "registry.advantest.com", "user": "ChangeToUserName", "password": "ChangeToSecret" }, "containers": [ { "name": "dpat-app", "image": "adv-dpat/adv-dpat-v1:ExampleTag", "environment" : { "ONEAPI_DEBUG": "3", "ONEAPI_CONTROL_ZMQ_IP": "ChangeToHostControllerIp" } } ] } }
Edit /opt/acs/nexus/conf/acs_nexus.ini file.
Make sure the Auto_Deploy option is false
[Auto_Deploy] Enabled=false
Make sure the Enabled option is true in TestFloor_Server section
[TestFloor_Server] Enabled=true Control_Port=5001 Data_Port=5002 Heartbeat_Cycle=10 ;; unit s
Restart acs_nexus service
sudo systemctl restart acs_nexus
Confirm floor_service process is running
ps -ef|grep acs
Output: you can see floor_service process is running
$ ps -ef|grep acs root 10140 1 0 11:05 ? 00:00:00 /opt/acs/nexus/bin/mesh_server -c /opt/ acs/nexus/conf/mesh.conf root 10142 1 0 11:05 ? 00:00:00 /opt/acs/nexus/bin/acs_nexus root 10187 1 1 11:05 ? 00:00:05 /opt/acs/nexus/bin/floor_service root 10194 1 0 11:05 ? 00:00:01 /opt/acs/nexus/bin/ monitoring_data_uploader -c /opt/acs/nexus/conf/monitor/monitor.conf root 10313 1 0 11:05 ? 00:00:00 /bin/bash /opt/hp93000/testcell/bin/run / opt/acs/nexus/bin/control_smt8 root 10332 1 0 11:05 ? 00:00:00 /opt/acs/nexus/bin/rtdf_writing_service & root 10405 10313 0 11:05 ? 00:00:00 /opt/acs/nexus/bin/control_smt8 root 10636 1 0 11:05 ? 00:00:00 /opt/acs/nexus/bin/metrics_monitor &
Run the SmarTest test program to trigger DPAT app running with DFF#
Note, please ensure you have switched to SmarTest8
Running the Test Program#
Start SmarTest8
Run the script that starts SmartTest8:
cd ~/apps/application-dpat-v3.1.0 sh start_smt8.sh
Nexus TPI
You can find “NexusTPI.jar” in the project build path. This dynamic library is used for bi-directional communicating between Test program and Nexus.
You can find the involking NexusTPI codes in in the test method file measuredValueFileReader.java
Click to expand!
/**
*
*/
package misc;
import java.time.Instant;
import java.util.List;
import java.util.Random;
import org.json.JSONObject;
import base.SOCTestBase;
import nexus.tpi.NexusTPI;
import shifter.GlobVars;
import xoc.dta.annotations.In;
import xoc.dta.datalog.IDatalog;
import xoc.dta.datatypes.MultiSiteDouble;
import xoc.dta.measurement.IMeasurement;
import xoc.dta.resultaccess.IPassFail;
import xoc.dta.testdescriptor.IFunctionalTestDescriptor;
import xoc.dta.testdescriptor.IParametricTestDescriptor;
/**
* ACS Variable control and JSON write demo using SMT8 for Washington
*/
@SuppressWarnings("unused")
public class measuredValueFileReader extends SOCTestBase {
public IMeasurement measurement;
public IParametricTestDescriptor pTD;
public IFunctionalTestDescriptor fTD;
public IFunctionalTestDescriptor testDescriptor;
class params {
private String _upper;
private String _lower;
private String _unit;
public params(String _upper, String lower, String _unit) {
super();
this._upper = _upper;
this._lower = lower;
this._unit = _unit;
}
}
@In
public String testName;
String testtext = "";
String powerResult = "";
int hb_value;
double edge_min_value = 0.0;
double edge_max_value = 0.0;
double prev_edge_min_value = 0.0;
double prev_edge_max_value = 0.0;
boolean c0Flag = false;
boolean c1Flag = false;
String[] ecid_strs = {"U6A629_03_x1_y2", "U6A629_03_x1_y3", "U6A629_03_x1_y4", "U6A629_03_x2_y1", "U6A629_03_x2_y2", "U6A629_03_x2_y6", "U6A629_03_x2_y7", "U6A629_03_x3_y10", "U6A629_03_x3_y2", "U6A629_03_x3_y3", "U6A629_03_x3_y7", "U6A629_03_x3_y8", "U6A629_03_x3_y9", "U6A629_03_x4_y11", "U6A629_03_x4_y1", "U6A629_03_x4_y2", "U6A629_03_x4_y4", "U6A629_03_x5_y0", "U6A629_03_x5_y10", "U6A629_03_x5_y11", "U6A629_03_x5_y3", "U6A629_03_x5_y7", "U6A629_03_x5_y8", "U6A629_03_x6_y3", "U6A629_03_x6_y5", "U6A629_03_x6_y6", "U6A629_03_x6_y7", "U6A629_03_x7_y4", "U6A629_03_x7_y7", "U6A629_03_x8_y2", "U6A629_03_x8_y3", "U6A629_03_x8_y5", "U6A629_03_x8_y7", "U6A629_04_x1_y2", "U6A629_04_x2_y2", "U6A629_04_x2_y3", "U6A629_04_x2_y7", "U6A629_04_x2_y8", "U6A629_04_x2_y9", "U6A629_04_x3_y10", "U6A629_04_x3_y2", "U6A629_04_x3_y3", "U6A629_04_x3_y4", "U6A629_04_x3_y5", "U6A629_04_x3_y7", "U6A629_04_x3_y9", "U6A629_04_x4_y11", "U6A629_04_x4_y2", "U6A629_04_x4_y7", "U6A629_04_x4_y8", "U6A629_04_x4_y9", "U6A629_04_x5_y4", "U6A629_04_x5_y7", "U6A629_04_x6_y5", "U6A629_04_x6_y6", "U6A629_04_x6_y8", "U6A629_04_x7_y10", "U6A629_05_x2_y2", "U6A629_05_x3_y0", "U6A629_05_x4_y1", "U6A629_05_x4_y2", "U6A629_05_x5_y1", "U6A629_05_x5_y2", "U6A629_05_x5_y3", "U6A629_05_x6_y1", "U6A629_05_x6_y3", "U6A629_05_x7_y2", "U6A629_05_x7_y3", "U6A629_05_x8_y3", "U6A633_10_x4_y9", "U6A633_10_x8_y9", "U6A633_11_x2_y2", "U6A633_11_x3_y9", "U6A633_11_x5_y2", "U6A633_11_x6_y10", "U6A633_11_x6_y5", "U6A633_11_x7_y9", "U6A633_11_x8_y8", "U6A633_11_x8_y9", "U6A633_12_x2_y3", "U6A633_12_x2_y5", "U6A633_12_x2_y7", "U6A633_12_x2_y9", "U6A633_12_x3_y1", "U6A633_12_x3_y9", "U6A633_12_x4_y0", "U6A633_12_x5_y1", "U6A633_12_x7_y4"};
int ecid_ptr = 0;
long hnanosec = 0;
List<Double> current_values;
protected IPassFail digResult;
public String pinList;
@Override
public void update() {
}
@SuppressWarnings("static-access")
@Override
public void execute() {
int resh;
int resn;
int resx;
IDatalog datalog = context.datalog(); // use in case logDTR does not work
int index = 0;
Double raw_value = 0.0;
String rvalue = "";
String low_limitStr = "";
String high_limitStr = "";
Double low_limit = 0.0;
Double high_limit = 0.0;
String unit = "";
String packetValStr = "";
String sku_name = "";
String command = "";
/**
* This portion of the code will read an external datalog file in XML and compare data in
* index 0 to the limit variables received from Nexus
*/
if (testName.contains("RX_gain_2412_C0_I[1]")) {
try {
NexusTPI.target("dpat-app").timeout(1);
Instant hinstant = Instant.now();
GlobVars.hsnanoSeconds = (hinstant.getEpochSecond()*1000000000) + hinstant.getNano();
System.out.println("HealthCheck Start time= "+GlobVars.hsnanoSeconds);
String jsonHRequest = "{\"health\":\"DoHealthCheck\"}";
int hres = NexusTPI.request(jsonHRequest);
System.out.println("BiDir-request Response= "+hres);
String hresponse = NexusTPI.getResponse();
System.out.println("BiDir:: getRequest Health Response:"+hresponse);
Instant instant = Instant.now();
GlobVars.henanoSeconds = (instant.getEpochSecond()*1000000000) + instant.getNano();
System.out.println("HealthCheck Stop time= "+GlobVars.henanoSeconds);
hparse(hresponse);
} catch (Exception e) {
e.printStackTrace();
throw e;
}
}
if ((testName.contains("RX_gain_2412_C0_I[1]")) && (!c0Flag)) {
try {
misc.XMLParserforACS.params key = GlobVars.c0_current_params.get(testName);
} catch (Exception e) {
System.out.println("Missing entry in maps for this testname : " + testName);
return;
}
try {
GlobVars.c0_current_values = new XMLParserforACS().parseXMLandReturnRawValues(testName);
} catch (NullPointerException e) {
System.out.print("variable has null value, exiting.\n");
}
try {
GlobVars.c0_current_params = new XMLParserforACS().parseXMLandReturnLimitmap(testName);
} catch (NullPointerException e) {
System.out.print("variable has null value, exiting.\n");
}
c0Flag = true;
low_limit = Double.parseDouble(GlobVars.c0_current_params.get(testName).getLower());
high_limit = Double.parseDouble(GlobVars.c0_current_params.get(testName).getUpper());
unit = GlobVars.c0_current_params.get(testName).getUnit();
GlobVars.orig_LoLim = low_limit;
GlobVars.orig_HiLim = high_limit;
}
if ((testName.contains("RX_gain_2412_C1_I[1]")) && (!c1Flag)) {
try {
misc.XMLParserforACS.params key = GlobVars.c1_current_params.get(testName);
} catch (Exception e) {
System.out.println("Missing entry in maps for this testname : " + testName);
return;
}
try {
GlobVars.c1_current_values = new XMLParserforACS().parseXMLandReturnRawValues(testName);
} catch (NullPointerException e) {
System.out.print("variable has null value, exiting.\n");
}
try {
GlobVars.c1_current_params = new XMLParserforACS().parseXMLandReturnLimitmap(testName);
} catch (NullPointerException e) {
System.out.print("variable has null value, exiting.\n");
}
c1Flag = true;
low_limit = Double.parseDouble(GlobVars.c1_current_params.get(testName).getLower());
high_limit = Double.parseDouble(GlobVars.c1_current_params.get(testName).getUpper());
unit = GlobVars.c1_current_params.get(testName).getUnit();
}
if (testName.contains("RX_gain_2412_C1_I[1]")) {
index = GlobVars.c1_index;
raw_value = GlobVars.c1_current_values.get(index);
low_limit = Double.parseDouble(GlobVars.c1_current_params.get(testName).getLower());
high_limit = Double.parseDouble(GlobVars.c1_current_params.get(testName).getUpper());
unit = GlobVars.c1_current_params.get(testName).getUnit();
}
if (testName.contains("RX_gain_2412_C0_I[1]")) {
index = GlobVars.c0_index;
raw_value = GlobVars.c0_current_values.get(index);
low_limit = Double.parseDouble(GlobVars.c0_current_params.get(testName).getLower());
high_limit = Double.parseDouble(GlobVars.c0_current_params.get(testName).getUpper());
unit = GlobVars.c0_current_params.get(testName).getUnit();
}
if (testName.contains("RX_gain_2412_C0_I[1]")) {
int res;
try {
System.out.println("ECID["+ecid_ptr+"] = "+ecid_strs[ecid_ptr]);
packetValStr = buildPacketString();
rvalue = String.valueOf(raw_value);
low_limitStr = String.valueOf(low_limit);
high_limitStr = String.valueOf(high_limit);
sku_name = "{\"SKU_NAME\":{\"MSFT_ECID\":\""+ecid_strs[ecid_ptr]+"\",\"testname\":\""+testName+"\",\"RawValue\":\""+rvalue+"\",\"LowLim\":\""+low_limitStr+"\",\"HighLim\":\""+high_limitStr+"\",\"packetString\":\""+packetValStr+"\"}}";
System.out.println("\nJson String sku_name length= "+sku_name.length());
Instant instant = Instant.now();
GlobVars.ssnanoSeconds = (instant.getEpochSecond()*1000000000) + instant.getNano();
System.out.println("TPSend Start Time= "+GlobVars.ssnanoSeconds);
res = NexusTPI.send(sku_name);
Instant pinstant = Instant.now();
GlobVars.senanoSeconds = (pinstant.getEpochSecond()*1000000000) + pinstant.getNano();
System.out.println("TPSend Return Time= "+GlobVars.senanoSeconds);
} catch (Exception e) {
e.printStackTrace();
throw e;
}
try {
long millis = 200;
Thread.sleep(millis);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
try {
Instant ginstant = Instant.now();
GlobVars.rsnanoSeconds = (ginstant.getEpochSecond()*1000000000) + ginstant.getNano();
System.out.println("RqstHostTime TPRqst Start= "+GlobVars.rsnanoSeconds);
String jsonRequest = "{\"request\":\"CalcNewLimits\"}";
res = NexusTPI.request(jsonRequest);
System.out.println("BiDir-request Response= "+res);
String response = NexusTPI.getResponse();
System.out.println("BiDir-getRequest Response= "+response);
Instant rinstant = Instant.now();
GlobVars.renanoSeconds = (rinstant.getEpochSecond()*1000000000) + rinstant.getNano();
System.out.println("Request Return Time= "+GlobVars.renanoSeconds);
parse(response);
} catch (Exception e) {
e.printStackTrace();
throw e;
}
}
if ((testName.contains("RX_gain_2412_C0_I[1]")) && (!GlobVars.limFlag)) {
low_limit = Double.parseDouble(GlobVars.adjlolimStr);
high_limit = Double.parseDouble(GlobVars.adjhilimStr);
}
System.out.println(testName + ": TestingText= " + testtext);
System.out.println(testName + ": low_limit= " + low_limit);
System.out.println(testName + ": high_limit= " + high_limit);
System.out.println("Simulated Test Value Data ");
System.out.println(
"testname = " + testName + " lower = " + low_limit + " upper = " + high_limit
+ " units = " + unit + " raw_value = " + raw_value + " index = " + index);
MultiSiteDouble rawResult = new MultiSiteDouble();
for (int site : context.getActiveSites()) {
rawResult.set(site, raw_value);
}
/** This performs datalog limit evaluation and p/f result and EDL datalogging */
pTD.setHighLimit(high_limit);
pTD.setLowLimit(low_limit);
pTD.evaluate(rawResult);
if (testName.contains("RX_gain_2412_C0_I[1]")) {
if (GlobVars.c0_index < (GlobVars.c0_current_values.size() - 1)) {
GlobVars.c0_index++;
} else {
GlobVars.c0_index = 0;
}
}
if (testName.contains("RX_gain_2412_C1_I[1]")) {
if (GlobVars.c1_index < (GlobVars.c1_current_values.size() - 1)) {
GlobVars.c1_index++;
} else {
GlobVars.c1_index = 0;
}
}
if (pTD.getPassFail().get()) {
System.out.println(
"Sim Value Test " + testName + "\n************ PASSED **************\n");
} else {
System.out.println(testName + "\n************ FAILED *****************\n");
}
if (testName.contains("RX_gain_2412_C0_I[1]")) {
// HTTP performance data: HealthCheck, POST, GET transactions
System.out.println("************ Nexus BiDir Performance Data ******************");
System.out.println("HealthCheck: Host to App Time= "+GlobVars.perf_times.get("Health_h-a_time"));
System.out.println("HealthCheck: App to Host Time= "+GlobVars.perf_times.get("Health_a-h_time"));
System.out.println("HealthCheck: Round-Trip Time= "+GlobVars.perf_times.get("Health_rtd_time"));
System.out.println("TPSend: Host to App Time= "+GlobVars.perf_times.get("Send_h-a_time"));
System.out.println("TPSend: App to Host Time= "+GlobVars.perf_times.get("Send_a-h_time"));
System.out.println("TPSend: Round-Trip Time= "+GlobVars.perf_times.get("Send_rtd_time"));
System.out.println("TPRequest: Host to App Time= "+GlobVars.perf_times.get("Request_h-a_time"));
System.out.println("TPRequest: App to Host Time= "+GlobVars.perf_times.get("Request_a-h_time"));
System.out.println("TPRequest: Round-Trip Time= "+GlobVars.perf_times.get("Request_rtd_time"));
System.out.println("*****************************************************");
}
// Clear large strings used for http post
packetValStr = "";
sku_name = "";
ecid_ptr++;
if (ecid_ptr >= ecid_strs.length) {
ecid_ptr = 0;
}
}
public static String parse(String responseBody) {
if (responseBody.contains("MSFT_ECID")) {
JSONObject results = new JSONObject(responseBody);
String ecid = results.getString("MSFT_ECID");
System.out.println("MSFT_ECID: " + ecid);
String testName = results.getString("testname");
System.out.println("testname: " + testName);
GlobVars.adjlolimStr = results.getString("AdjLoLim");
System.out.println("AdjLoLim: " + GlobVars.adjlolimStr);
GlobVars.adjhilimStr = results.getString("AdjHiLim");
System.out.println("AdjHiLim: " + GlobVars.adjhilimStr);
String sndappTime = results.getString("SendAppTime");
System.out.println("SendAppTime: " + sndappTime);
String sretappTime = results.getString("SendAppRetTime");
System.out.println("SendAppRetTime: " + sretappTime);
String rappTime = results.getString("RqstAppTime");
System.out.println("RqstAppTime: " + rappTime);
String rretappTime = results.getString("RqstAppRetTime");
System.out.println("RqstAppRetTime: " + rretappTime);
long atime = Long.parseLong(sndappTime);
long artime = Long.parseLong(sretappTime);
long ratime = Long.parseLong(rappTime);
long rartime = Long.parseLong(rretappTime);
double deltaSndTime = (atime - GlobVars.ssnanoSeconds)/1000000.0; // Delta time in msec
GlobVars.perf_times.put("Send_h-a_time", deltaSndTime);
System.out.println("Delta TPSend h-a app-host time: "+deltaSndTime+" msec");
double deltaSndRetTime = (GlobVars.senanoSeconds - artime)/1000000.0; // Delta time in msec
GlobVars.perf_times.put("Send_a-h_time", deltaSndRetTime);
System.out.println("Delta TPSend a-h time: "+deltaSndRetTime+" msec");
double sendDeltaTime = (GlobVars.senanoSeconds - GlobVars.ssnanoSeconds)/1000000.0; // Delta time in msec
GlobVars.perf_times.put("Send_rtd_time", sendDeltaTime);
System.out.println("Delta TPSend transaction time: "+sendDeltaTime+" msec");
double deltaRqstTime = (ratime - GlobVars.rsnanoSeconds)/1000000.0; // Delta time in msec
GlobVars.perf_times.put("Request_h-a_time", deltaRqstTime);
System.out.println("Delta TPRequest h-a time: "+deltaRqstTime+" msec");
double deltaRqstRetTime = (GlobVars.renanoSeconds - rartime)/1000000.0; // Delta time in msec
GlobVars.perf_times.put("Request_a-h_time", deltaRqstRetTime);
System.out.println("Delta TPRequest a-h time: "+deltaRqstRetTime+" msec");
double gadeltaTime = (GlobVars.renanoSeconds - GlobVars.rsnanoSeconds)/1000000.0; // Delta time in msec
GlobVars.perf_times.put("Request_rtd_time", gadeltaTime);
// GlobVars.rsnanoSeconds = 0; // clear for next device
}
return responseBody;
}
public static String hparse(String responseBody) {
String hatime = "0";
if (responseBody.contains("health")) {
JSONObject results = new JSONObject(responseBody);
hatime = results.getString("health");
long hatimeval = Long.parseLong(hatime);
System.out.println("health: " + hatime);
double hsdeltaTime = (hatimeval - GlobVars.hsnanoSeconds)/1000000.0; // Delta time in msec
double hrdeltaTime = (GlobVars.henanoSeconds - hatimeval)/1000000.0; // Delta time in msec
double rhdeltaTime = (GlobVars.henanoSeconds - GlobVars.hsnanoSeconds)/1000000.0; // Delta time in msec
GlobVars.perf_times.put("Health_h-a_time", hsdeltaTime);
GlobVars.perf_times.put("Health_a-h_time", hrdeltaTime);
GlobVars.perf_times.put("Health_rtd_time", rhdeltaTime);
System.out.println("Delta health h-a time: "+hsdeltaTime+" msec");
System.out.println("Delta health a-h time: "+hrdeltaTime+" msec");
System.out.println("Delta health rtd time: "+rhdeltaTime+" msec");
}
return hatime;
}
public String buildPacketString() {
int packetSel = GlobVars.packetSelector;
int[] cnt_values = { 203, 1000, 10000, 100000, 1000000,
2000000, 3000000, 4000000, 5000000,
6000000, 7000000, 8000000, 9000000,
10000000, 20000000, 40000000, 60000000, 80000000, 100000000,
120000000, 140000000, 160000000, 180000000, 200000000, 220000000,
240000000, 260000000, 280000000, 300000000};
System.out.println("PacketID: " + packetSel);
String pktStr = "";
int chrcnt = cnt_values[packetSel] - 200; // was 146;
System.out.println("Chrcnt: " + chrcnt);
String valstr = "";
String BUILDCHARS = "ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890";
StringBuilder packetstr = new StringBuilder();
Random rnd = new Random();
while (packetstr.length() < chrcnt) { // length of the random string.
int index = (int) (rnd.nextFloat() * BUILDCHARS.length());
packetstr.append(BUILDCHARS.charAt(index));
}
pktStr = packetstr.toString();
GlobVars.packetStr = pktStr;
return pktStr;
}
}
Activate Testflow:
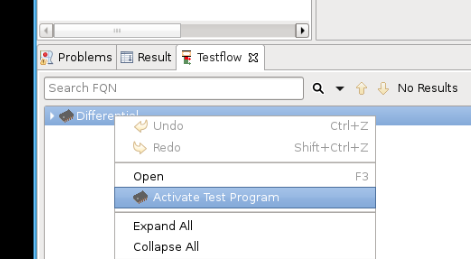
To activate the Testflow, you’ll need to right-click on the Testflow entry at the bottom and then select “Activate…”:
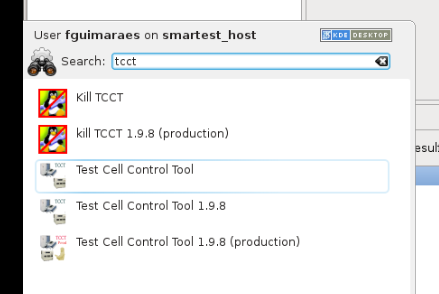
From the Red Hat menu, open TCCT:
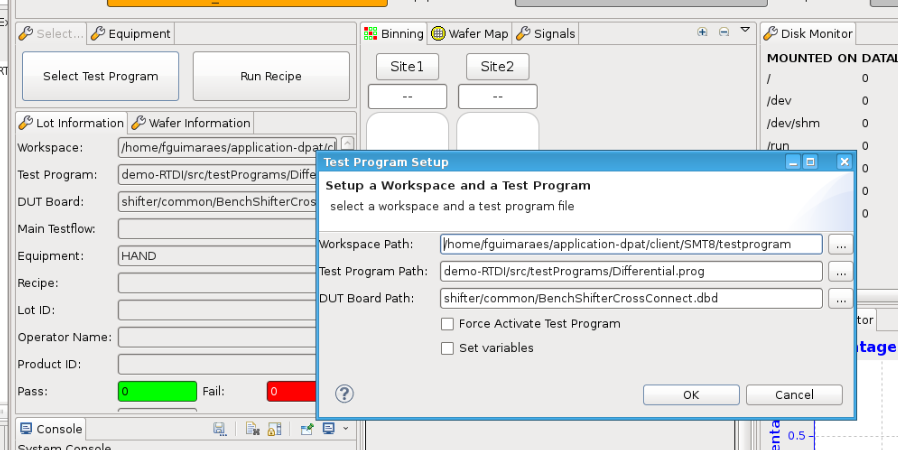
Click on “Select Test Program”, select the “Differential” testflow and then “OK”:
By running TCCT (just selecting the testprogram), an event is triggered and the DPAT container automatically starts running on the ACS Edge Server.
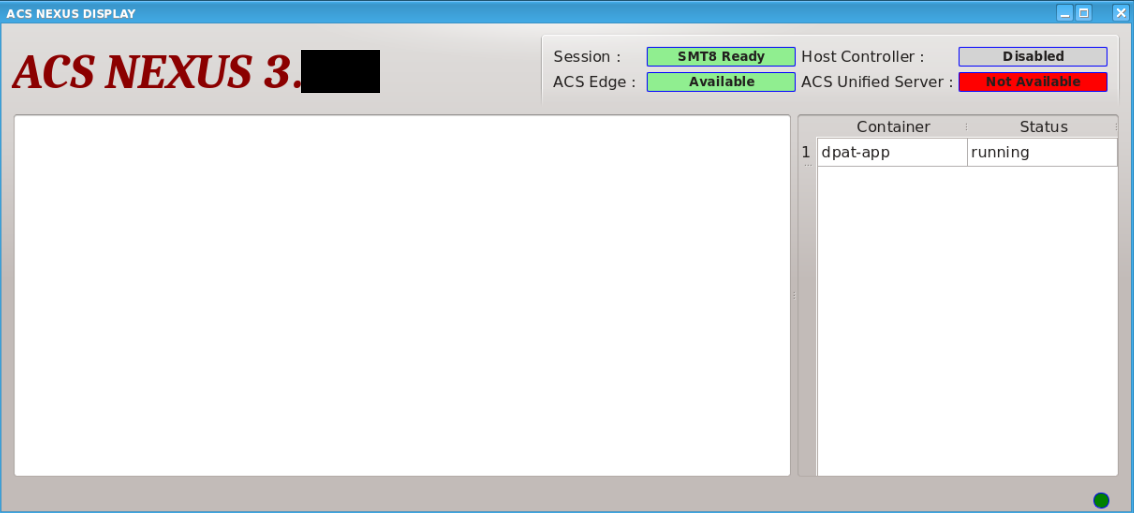
Once the container is running (verify via the Nexus UI), right-click on the “Differential” and then “Activate” and “Run”. This will send parametric data into the container.
Visualize Results#
To witness the limit changes, open the Result perspective in SmarTest8. In the Test tab, the new limits will be displayed:
Note that: In contrast to run test program without DFF, the new limits vary with each test program execution, as they are determined by parametric random test values.
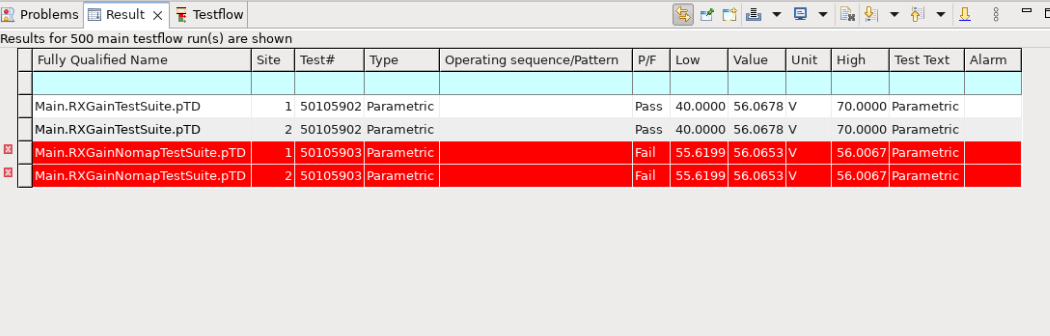
Running test program without DFF, the test limits are same for the first running test program after SmarTest being launched.
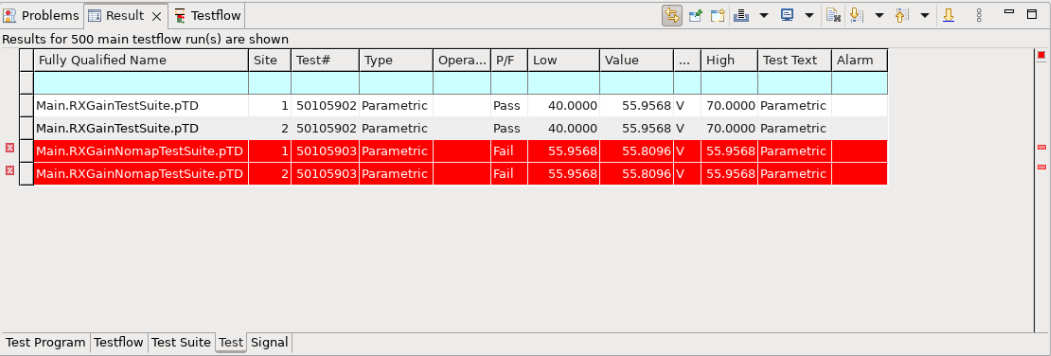
Notice the Lower and Upper limits changes. After this, you can close SmarTest8. By closing SMT8, the container will be automatically stopped and deleted.
As querying Docker logs app is based on Edge SDK which has issues, it is not available on current version and will be fixed on next version.
Access Container Logs to confirm DFF is working#
After the Testprogram has been run, the container logs (from stdout) can be accessed using the get_edge_logs.sh script, located in the project root folder.
Compile the code in the terminal:
cd ~/apps/application-dpat-v3.1.0/docker_logs/
make clean
make
Run this command to print the logs and to save them to a file:
cd ~/apps/application-dpat-v3.1.0/
sh get_edge_logs.sh ChangeToEdgeIp ChangeToContainerName
You can get the log like the following, it illustrates the DFF is working.
sh get_edge_logs.sh ChangeToEdgeIp ChangeToContainerName | grep "Retrieve previous data from DFF"
Output
{\"testerId\": null, \"edgeServerId\": null, \"applicationId\": \"dpat-app\", \"timestamp\": \"1748246447\", \"level\": \"INFO\", \"message\": \"Retrieve previous data from DFF, data = [55.9567985535, 55.9567985535]\"}
{\"testerId\": null, \"edgeServerId\": null, \"applicationId\": \"dpat-app\", \"timestamp\": \"1748246452\", \"level\": \"INFO\", \"message\": \"Retrieve previous data from DFF, data = [55.8096008301, 55.8096008301]\"}
The full log will be located at:
vim ~/apps/application-dpat-v3.1.0/docker_logs/edge_logs.txt