Use the model developed by user and run it in RTDI environment#
About this tutorial#
In this tutorial you will learn how to:
Create a do-it-yourself (DIY) App for ACS Edge that does statistical data processing
Integrate this App with a SmarTest 7 test program
The tutorial makes use of the Advantest Demo App for Dynamic Part Average Testing (DPAT) on ACS Edge.
Compatibility#
SmarTest 7 / Nexus 3.1.0 / Edge 3.4.0-prod
Before you begin#
Ensure you have the following prepared:
An RTDI virtual environment containing a Host Controller VM and an Edge Server VM
An ACS Container Hub user account and an ACS Container Hub project
Procedure#
Note: The ‘adv-dpat’ project we are using below is for demonstration purposes. You will need to replace it with your own project accordingly.
1. Create RTDI virtual environment from the “Virtual Machine” page#
Click the “ADD” button at the top right of the “Virtual Machine” page
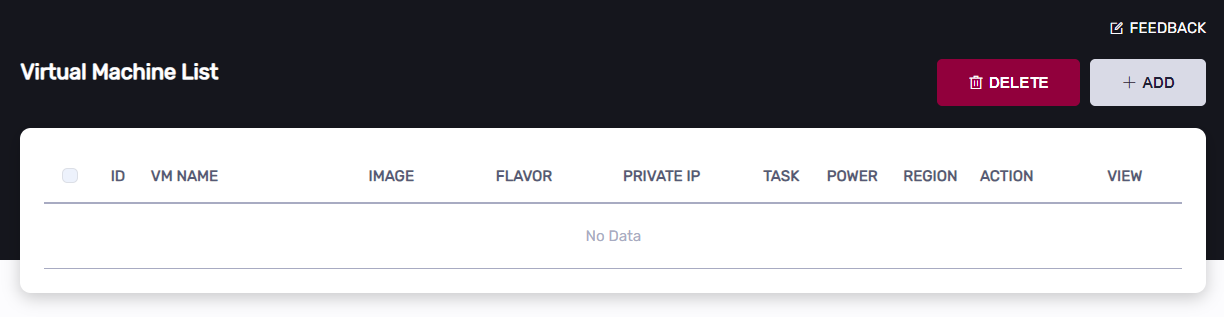
In the popped up dialog, enter “VM Name” and “Login Name”, select “Host Controller” and “Edge Server”, then click the “SUBMIT” button.
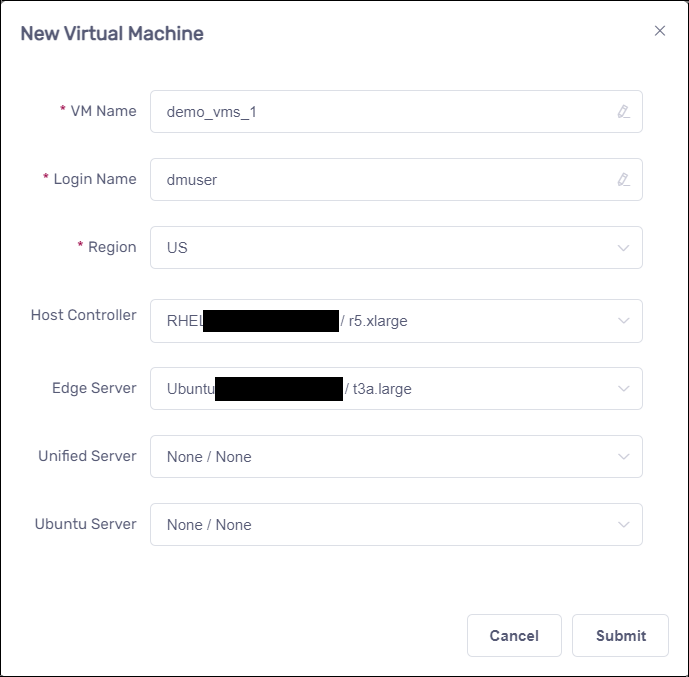
Wait about 5 minutes for the VMs to be created. The new VMs will appear in the virtual machine list with their status as “UP”.
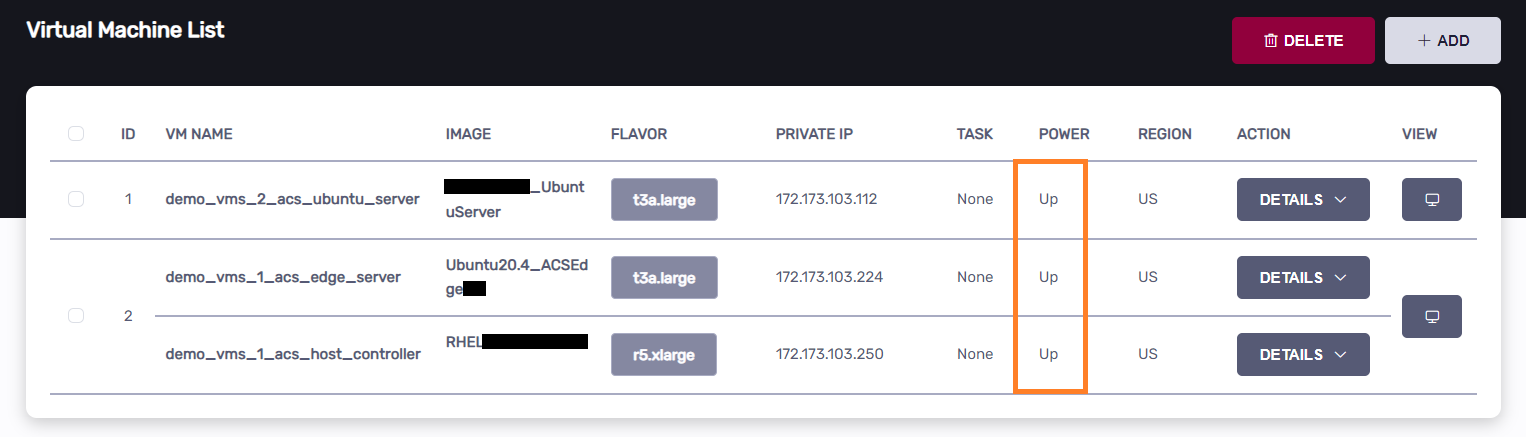
Click the “VIEW” button to access the Host Controller VM when it is ready.
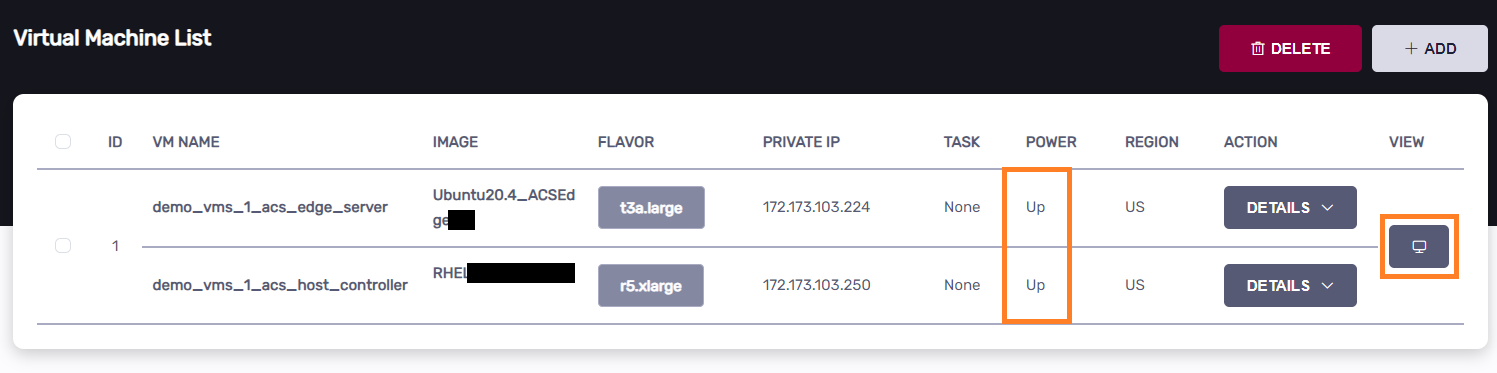
Click the “VNC” button to access the Host Controller VM in a new tab.
2. Transfer demo program#
Click to download the application-dpat-v3.1.0-RHEL74.tar.gz archive(a simple DPAT algorithm in Python) to your computer.
Transfer the file to the ~/apps directory on the Host Controller VM, refer to the “Transferring files” section of VM Management page.
In the VNC GUI, extract files in the bash console.
cd ~/apps/
tar zxf application-dpat-v3.1.0-RHEL74.tar.gz
3. Develop a DIY DPAT App as a container image#
Navigate to the DPAT app directory
cd ~/apps/application-dpat-v3.1.0/rd-app_dpat_py
You will find the following files:
Dockerfile: this is used for building DPAT app docker image
Click to expand!
FROM registry.advantest.com/adv-dpat/python39-basic:2.0
RUN yum install -y openssh-server
RUN mkdir /var/run/sshd
RUN echo 'root:root123' | chpasswd
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed 's@session\s*required\s*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd
EXPOSE 22
# set nexus env variables
WORKDIR /
RUN python3.9 -m pip install pandas jsonschema
# copy run files and directories
RUN mkdir -p /dpat-app;chmod a+rwx /dpat-app
RUN mkdir -p /dpat-app/data;chmod a+rwx /dpat-app/data
RUN touch dpat-app/__init__.py
COPY workdir /dpat-app/workdir
COPY conf /dpat-app/conf
# RUN yum -y install libunwind-devel
RUN echo 'export $(cat /proc/1/environ |tr "\0" "\n" | xargs)' >> /etc/profile
ENV LOG_FILE_PATH "/tmp/app.log"
ENV DFF_FLAG="False"
WORKDIR /dpat-app/workdir
RUN /usr/bin/ssh-keygen -A
RUN echo "python3.9 -u /dpat-app/workdir/run_dpat.py&" >> /start.sh
RUN echo "/usr/sbin/sshd -D" >> /start.sh
CMD sh /start.sh
workdir/dpat.py: this is the core algorithm for DPAT calculation
Click to expand!
""" Copyright 2023 ADVANTEST CORPORATION. All rights reserved
This module contains a class and modules that allow the user to calculate new limits
based on dynamic part average testing. It is assumed that this is being run on the
docker container with the Nexus connection, being called by run_dpat.py.
"""
import time
from typing import Dict, List
import numpy as np
import pandas as pd
class DPAT:
"""
This class allows the user to calculate new limits based on dynamic part average
testing. It is assumed that this is being run on the docker container with the Nexus
connection. Contains the following methods:
* save_stat(results, df_cumulative_raw, args)
* check_new_limits(df_new_limits)
* save_stat(results, df_cumulative_raw, args)
* stdev_compute(df_cumulative_raw, return_columns)
* stdev_full_compute(df_stdev_full, return_columns)
* iqr_full_compute(df_iqr_full, return_columns)
* iqr_window_compute(df_iqr_full, return_columns)
* stdev_compute(df_cumulative_raw, return_columns)
* compute(df_base_limits, df_cumulative_raw, args)
* datalog(nexus_data, df_base_limits, df_cumulative_raw, args)
* run(data, args)
* main - the main function of the script
"""
def __init__(self, ):
self.counter = 0
def compute_once(self, nexus_data: pd.DataFrame, base_limits: pd.DataFrame, logger, args):
"""Preprocess data, setting base values and columns. Should run only once.
Args:
nexus_data: string with pin values coming from nexus
base_limits: DataFrame with base limits and parameters
args: Dictionary with arguments set on main by user
"""
self.counter += 1
self.nexus_data = nexus_data
self.args = args
self.logger = logger
self.df_base_limits, self.df_cumulative_raw = self.preprocess_data(base_limits)
def save_stat(
self, results: pd.DataFrame, df_cumulative_raw: pd.DataFrame, args: Dict
):
"""Save new limits and raw file into csv.
Args:
df_base_limits: DataFrame with base limits and parameters
df_cumulative_raw: DataFrame with base values and columns
args: Dictionary with argsurations parameters set from user
"""
self.logger.info("=> Start save_stat")
set_path_storage = args.get("setPathStorage")
set_prefix_storage = args.get("setPrefixStorage")
file_to_save_raw = set_path_storage + "/" + set_prefix_storage + "_raw.csv"
file_to_save = set_path_storage + "/" + set_prefix_storage + "_stdev.csv"
df_cumulative_raw.to_csv(file_to_save_raw, mode="a", index=False)
results.to_csv(file_to_save, mode="a", index=False)
self.logger.info("=> End save_stat")
def check_new_limits(self, df_new_limits: pd.DataFrame) -> List:
"""Check new limits against existing thresholds and return ids that are off limits.
The ids that don't meet the criteria are resetted to base limits.
Args:
df_new_limits: DataFrame calculated limits
Return:
test_ids: List with test_ids that are off the base limits
"""
# New limits that are below user defined threshold
below_threshold = df_new_limits[
(df_new_limits["limit_Usl"] - df_new_limits["limit_Lsl"]) <
(df_new_limits["PassRangeUsl"] - df_new_limits["PassRangeLsl"]) *
df_new_limits["DPAT_Threshold"]
]
# New limits that are below base lower limit
below_lsl = df_new_limits[
(df_new_limits["N"] < df_new_limits["DPAT_Samples"]) |
(df_new_limits["limit_Lsl"] < df_new_limits["PassRangeLsl"]) *
df_new_limits["DPAT_Threshold"]
]
# New limits that are above base upper limit
above_usl = df_new_limits[
(df_new_limits["N"] < df_new_limits["DPAT_Samples"]) |
(df_new_limits["limit_Usl"] > df_new_limits["PassRangeUsl"]) *
df_new_limits["DPAT_Threshold"]
]
test_ids = []
if not above_usl.empty:
test_ids = above_usl.TestId.unique().tolist()
if not below_lsl.empty:
test_ids = test_ids + below_lsl.TestId.unique().tolist()
if not below_threshold.empty:
test_ids = test_ids + below_threshold.TestId.unique().tolist()
return list(set(test_ids)) # return unique testd_ids
def stdev_full_compute(
self, df_stdev_full: pd.DataFrame, return_columns: List
) -> pd.DataFrame:
"""Compute stdev method for specific test_ids.
It updates the lower and upper limits following this formula:
LPL = Mean - <dpat_sigma> * Sigma
UPL = Mean + <dpat_sigma> * Sigma,
Where <dpat_sigma> is an user defined parameter.
Args:
df_stdev_full: DataFrame with base values and columns
return_columns: Columns to filter returned dataframe on
Return:
df_result: DataFrame with calculated stdev full and specific return columns
"""
df_stdev_full.loc[:, 'N'] = \
df_stdev_full.groupby('TestId')['TestId'].transform('count').values
df_n = df_stdev_full[df_stdev_full["N"] > 1]
df_one = df_stdev_full[df_stdev_full["N"] <= 1]
mean = df_n.groupby("TestId")["PinValue"].transform("mean")
stddev = df_n.groupby("TestId")["PinValue"].transform(lambda x: np.std(x, ddof=1))
# Calculate new limits according to stdev sample
df_n.loc[:, "stdev_all"] = stddev.values
df_n.loc[:, "limit_Lsl"] = (mean - (stddev * df_n["DPAT_Sigma"])).values
df_n.loc[:, "limit_Usl"] = (mean + (stddev * df_n["DPAT_Sigma"])).values
# Assign base limits to test_ids with a single instance
df_one.loc[:, "limit_Lsl"] = df_one["PassRangeLsl"].values
df_one.loc[:, "limit_Usl"] = df_one["PassRangeUsl"].values
df_one.loc[:, "stdev_all"] = 0
df_result = pd.concat([df_one, df_n])[return_columns].drop_duplicates()
return df_result
def stdev_window_compute(
self, df_stdev_window: pd.DataFrame, return_columns: List
) -> pd.DataFrame:
"""Compute stdev method for a specific window of test_ids.
The mean and sigma are calculated for that window, and then
it updates the lower and upper limits following this formula:
LPL = Mean - <dpat_sigma> * Sigma
UPL = Mean + <dpat_sigma> * Sigma,
Where <dpat_sigma> is an user defined parameter.
Args:
df_stdev_window: DataFrame with base values and columns
return_columns: Columns to filter returned dataframe on
Return:
df_result: DataFrame with calculated stdev window and specific return columns
"""
df_stdev_window.loc[:, 'N'] = \
df_stdev_window.groupby('TestId')['TestId'].transform('count').values
# Separate test_ids with more than one sample
df_n = df_stdev_window[df_stdev_window["N"] > 1]
df_one = df_stdev_window[df_stdev_window["N"] <= 1]
# Slice df according to window_size
df_stdev_window.loc[:, 'N'] = df_stdev_window["DPAT_Window_Size"].values
df_window_size = df_n.groupby("TestId").apply(
lambda x: x.iloc[int(-x.N.values[0]):]
).reset_index(drop=True)
if not df_n.empty:
# Calculate new limits
mean = df_window_size.groupby("TestId")["PinValue"].transform("mean").values
stddev = df_window_size.groupby("TestId")["PinValue"].transform(
lambda x: np.std(x, ddof=1)
).values
df_n.loc[:, "stdev_all"] = stddev
df_n.loc[:, "limit_Lsl"] = (mean - (stddev * df_n["DPAT_Sigma"])).values
df_n.loc[:, "limit_Usl"] = (mean + (stddev * df_n["DPAT_Sigma"])).values
# Assign base limits to test_ids with a single instance
df_one.loc[:, "limit_Lsl"] = df_one["PassRangeLsl"].values
df_one.loc[:, "limit_Usl"] = df_one["PassRangeUsl"].values
df_one.loc[:, "stdev_all"] = 0
df_result = pd.concat([df_n, df_one])[return_columns].drop_duplicates()
return df_result
def iqr_full_compute(
self, df_iqr_full: pd.DataFrame, return_columns: List
) -> pd.DataFrame:
"""
Update the lower and upper limits following this formula:
IQR = Upper Quartile(Q3) - Lower Quartile(Q1)
LSL = Q1 - 1.5 IQR
USL = Q3 + 1.5 IQR
Args:
df_iqr_full: DataFrame with base values and columns
return_columns: Columns to filter returned dataframe on
Return:
df_result: DataFrame with calculated IQR full and specific return columns
"""
window_size = df_iqr_full["DPAT_Window_Size"]
df_iqr_full.loc[:, "N"] = window_size
df_iqr_full.loc[:, 'N'] = df_iqr_full.groupby('TestId')['TestId'].transform('count')
# Separate test_ids with more than one sample
df_n = df_iqr_full[df_iqr_full["N"] > 1]
df_one = df_iqr_full[df_iqr_full["N"] <= 1]
if not df_n.empty:
# Compute new limits
first_quartile = df_n.groupby("TestId").PinValue.quantile(q=0.25)
upper_quartile = df_n.groupby("TestId").PinValue.quantile(q=0.75)
iqr = upper_quartile - first_quartile
multiple = df_n.groupby("TestId")["DPAT_IQR_Multiple"].first()
df_n = df_n[return_columns].drop_duplicates()
df_n.loc[:, "limit_Lsl"] = (first_quartile - (multiple * iqr)).values
df_n.loc[:, "limit_Usl"] = (upper_quartile + (multiple * iqr)).values
df_n.loc[:, "q1_all"] = first_quartile.values
df_n.loc[:, "q3_all"] = upper_quartile.values
# Assign base limits to test_ids with a single instance
df_one.loc[:, "limit_Lsl"] = df_one["PassRangeLsl"].values
df_one.loc[:, "limit_Usl"] = df_one["PassRangeUsl"].values
df_one["q1_all"] = df_one["q1_all"].astype('float64')
df_one["q3_all"] = df_one["q3_all"].astype('float64')
df_one.loc[:, "q1_all"] = np.nan
df_one.loc[:, "q3_all"] = np.nan
df_result = pd.concat([df_n, df_one])
return df_result[return_columns]
def iqr_window_compute(
self, df_iqr_window: pd.DataFrame, return_columns: List
) -> pd.DataFrame:
"""Before calculating the limits, it gets slices the df
according to the <window_size>.
Then it updates the lower and upper limits following this formula:
IQR = Upper Quartile(Q3) - Lower Quartile(Q1)
LSL = Q1 - 1.5 IQR
USL = Q3 + 1.5 IQR
Args:
df_iqr_window: DataFrame with base values and columns
return_columns: Columns to filter returned dataframe on
Return:
df_result: DataFrame with calculated IQR window and specific return columns
"""
window_size = df_iqr_window["DPAT_Window_Size"].values
df_iqr_window.loc[:, "window_size"] = window_size
df_iqr_window.loc[:, 'N'] = \
df_iqr_window.groupby('TestId')['TestId'].transform('count').values
# Separate test_ids with more than one sample
df_n = df_iqr_window[df_iqr_window["N"] > 1]
df_one = df_iqr_window[df_iqr_window["N"] <= 1]
if not df_n.empty:
# Slice df according to window_size
df_window_size = df_n.groupby("TestId").apply(
lambda x: x.iloc[int(-x.window_size.values[0]):]
).reset_index(drop=True)
# Calculate IQR
first_quartile = df_window_size.groupby(["TestId"]).PinValue.quantile(q=0.25)
upper_quartile = df_window_size.groupby(["TestId"]).PinValue.quantile(q=0.75)
iqr = upper_quartile - first_quartile
multiple = df_n.groupby("TestId")["DPAT_IQR_Multiple"].first()
df_n = df_n[return_columns].drop_duplicates()
# Calculate new limits
df_n.loc[:, "limit_Lsl"] = (first_quartile - (multiple * iqr)).values
df_n.loc[:, "limit_Usl"] = (upper_quartile + (multiple * iqr)).values
df_n.loc[:, "q1_window"] = first_quartile.values
df_n.loc[:, "q3_window"] = upper_quartile.values
# Assign base limits to test_ids with a single instance
df_one.loc[:, "limit_Lsl"] = df_one["PassRangeLsl"].values
df_one.loc[:, "limit_Usl"] = df_one["PassRangeUsl"].values
df_one["q1_window"] = df_one["q1_window"].astype('float64')
df_one["q3_window"] = df_one["q3_window"].astype('float64')
df_one.loc[:, "q1_window"] = np.nan
df_one.loc[:, "q3_window"] = np.nan
df_result = pd.concat([df_n, df_one])
return df_result[return_columns]
def stdev_sample_compute(
self, df_cumulative_raw: pd.DataFrame, return_columns: List
) -> pd.DataFrame:
"""
Updates the lower and upper limits following this formula:
LSL = Mean - <multiplier> * Sigma
USL = Mean + <multiplier> * Sigma
Args:
df_cumulative_raw: DataFrame with base values and columns
return_columns: Columns to filter returned dataframe on
Return:
df_stdev: DataFrame with calculated stdev and specific return columns
"""
df_stdev = df_cumulative_raw[
(df_cumulative_raw["DPAT_Type"] == "STDEV") & (df_cumulative_raw["nbr_executions"] > 1)
]
df_stdev_one = df_cumulative_raw[
(df_cumulative_raw["DPAT_Type"] == "STDEV") & (df_cumulative_raw["nbr_executions"] <= 1)
]
df_stdev.loc[:, "stdev"] = (
(
df_stdev["nbr_executions"] *
df_stdev["sum_of_squares"] -
df_stdev["sum"] * df_stdev["sum"]
) /
(
df_stdev["nbr_executions"] *
(df_stdev["nbr_executions"] - 1)
)
).pow(1./2).values
mean = (
df_stdev["sum"] /
df_stdev["nbr_executions"]
)
df_stdev.loc[:, "limit_Lsl"] = (mean - (df_stdev["stdev"] * df_stdev["DPAT_Sigma"])).values
df_stdev.loc[:, "limit_Usl"] = (mean + (df_stdev["stdev"] * df_stdev["DPAT_Sigma"])).values
df_stdev_one.loc[:, "limit_Lsl"] = df_stdev_one["PassRangeLsl"].values
df_stdev_one.loc[:, "limit_Usl"] = df_stdev_one["PassRangeUsl"].values
df_stdev = pd.concat([df_stdev, df_stdev_one])[return_columns]
return df_stdev
def compute(
self, df_base_limits: pd.DataFrame, df_cumulative_raw: pd.DataFrame, args: Dict
) -> pd.DataFrame:
"""Compute new limits with standard deviation and IQR methods
Args:
df_base_limits: DataFrame with base limits and parameters
df_cumulative_raw: DataFrame with base values and columns
args: Dictionary with args parameters set from user
Returns:
new_limits: DataFrame with new limits after compute
"""
self.logger.info("=>Starting Compute")
# define base columns and fill with NANs
df_cumulative_raw["stdev_all"] = np.nan
df_cumulative_raw["stdev_window"] = np.nan
df_cumulative_raw["stdev"] = np.nan
df_cumulative_raw["q1_all"] = np.nan
df_cumulative_raw["q3_all"] = np.nan
df_cumulative_raw["q1_window"] = np.nan
df_cumulative_raw["q3_window"] = np.nan
df_cumulative_raw["N"] = np.nan
df_cumulative_raw["limit_Lsl"] = np.nan
df_cumulative_raw["limit_Usl"] = np.nan
return_columns = [
"TestId", "stdev_all", "stdev_window", "stdev", "q1_all", "q3_all", "q1_window",
"q3_window", "N", "limit_Lsl", "limit_Usl", "PassRangeUsl", "PassRangeLsl"
]
in_time = time.time()
# Updates the lower and upper limits following this formula:
# LSL = Mean - <multiplier> * Sigma (sample)
# USL = Mean + <multiplier> * Sigma (sample)
df_stdev = self.stdev_sample_compute(df_cumulative_raw, return_columns)
# Updates the lower and upper limits according to sigma and mean
df_stdev_full = df_cumulative_raw[df_cumulative_raw["DPAT_Type"] == "STDEV_FULL"].copy()
df_stdev_full = self.stdev_full_compute(df_stdev_full, return_columns)
# Updates limits after getting a sample of <window_size>.
df_stdev_window = df_cumulative_raw[
df_cumulative_raw["DPAT_Type"] == "STDEV_RUNNING_WINDOW"
].copy()
df_stdev_window = self.stdev_window_compute(df_stdev_window, return_columns)
# Calculates limits based on Interquartile range.
# IQR = Upper Quartile(Q3) - Lower Quartile(Q1)
# LSL = Q1 - 1.5 IQR
# USL = Q3 + 1.5 IQR
df_iqr_full = df_cumulative_raw[df_cumulative_raw["DPAT_Type"] == "IQR_FULL"].copy()
df_iqr_full = self.iqr_full_compute(df_iqr_full, return_columns)
# Gets a sample of the dataframe of <window_size> and then uses IQR
df_iqr_window = df_cumulative_raw[df_cumulative_raw["DPAT_Type"] == "IQR_RUNNING_WINDOW"].copy()
df_iqr_window = self.iqr_window_compute(df_iqr_window, return_columns)
# Concatenates the 5 methods in one dataframe
new_limits_df = pd.concat(
[df_stdev, df_stdev_full, df_stdev_window, df_iqr_full, df_iqr_window]
).sort_values(by = "TestId").reset_index(drop=True)
# Check for test_ids that don't meet the criteria and are off limits
test_ids_off_limits = self.check_new_limits(new_limits_df.merge(df_base_limits))
if len(test_ids_off_limits) > 0:
# Sets the off limits ids to the base values
new_limits_df.loc[new_limits_df.TestId.isin(test_ids_off_limits), "limit_Usl"] = \
new_limits_df["PassRangeUsl"]
new_limits_df.loc[new_limits_df.TestId.isin(test_ids_off_limits), "limit_Lsl"] = \
new_limits_df["PassRangeLsl"]
new_limits_df["PassRangeLsl"] = new_limits_df["limit_Lsl"]
new_limits_df["PassRangeUsl"] = new_limits_df["limit_Usl"]
# Prepare dataframe with return format
new_limits_df = new_limits_df.merge(
df_cumulative_raw[["TestId", "TestSuiteName", "Testname", "pins"]].drop_duplicates(),
on = "TestId", how="left"
)
# Pick return columns and drop duplicates
new_limits_df = new_limits_df[[
"TestId", "TestSuiteName", "Testname", "pins", "PassRangeLsl", "PassRangeUsl",
]].drop_duplicates()
out_time = time.time()
self.logger.info("Compute Setup Test Time=%.3f} sec" % (out_time - in_time))
# Parameter set by user, persists result in a file
if args.get("saveStat"):
self.save_stat(
new_limits_df,
df_cumulative_raw,
args
)
self.logger.info("=> End Compute")
return new_limits_df
def format_result(self, result_df: pd.DataFrame) -> str:
"""Convert dataframe to string with variables to be used in VariableControl
Follows this format: TESTID0,value TESTID1,value TESTID2,value
"""
new_limits_df = result_df.copy()
new_limits_df.sort_values(by="TestId").reset_index(drop=True, inplace=True)
new_limits_df["test_id_var"] = "TestId" + new_limits_df.index.astype(str) + "," + \
new_limits_df["TestId"].astype(str)
test_ids = ' '.join(new_limits_df["test_id_var"])
new_limits_df["limits_lsl"] = "limit_lsl." + new_limits_df["TestId"].astype(str) + \
"," + new_limits_df["PassRangeLsl"].astype(str)
new_limits_df["limits_usl"] = "limit_usl." + new_limits_df["TestId"].astype(str) + \
"," + new_limits_df["PassRangeUsl"].astype(str)
limits_lsl = ' '.join(new_limits_df["limits_lsl"])
limits_usl = ' '.join(new_limits_df["limits_usl"])
variable_command = limits_lsl + " " + test_ids + " " + limits_lsl + " " + limits_usl
return variable_command
def datalog(self,) -> str:
"""Prepare data and compute new limits
Returns:
variable_command: formatted command with new_limits after compute
"""
nexus_data = self.nexus_data
df_base_limits = self.df_base_limits
df_cumulative_raw = self.df_cumulative_raw
args = self.args
self.logger.info("=> Starting Datalog")
start = time.time()
# Read string from nexus. Note that this does not read a csv file.
current_result_datalog = nexus_data
# Prepare base values and columns
df_cumulative_raw = df_cumulative_raw[["TestId", "sum", "sum_of_squares", "nbr_executions"]]
df_cumulative_raw = df_cumulative_raw.merge(current_result_datalog, on="TestId")
df_cumulative_raw["nbr_executions"] = df_cumulative_raw["nbr_executions"] + 1
df_cumulative_raw["sum"] = df_cumulative_raw["sum"] + df_cumulative_raw["PinValue"]
df_cumulative_raw["sum_of_squares"] = (
df_cumulative_raw["sum_of_squares"] +
df_cumulative_raw["PinValue"] * df_cumulative_raw["PinValue"]
)
df_cumulative_raw = df_cumulative_raw.merge(
df_base_limits, on="TestId", how="left"
)
# Compute new limits according to stdev and IQR methods
new_limits_df = self.compute(
df_base_limits,
df_cumulative_raw,
args
)
end = time.time()
self.logger.info(
"Total Setup/Parallel Computation and Return result Test Time=%f" % (end-start)
)
self.logger.info("=> End of Datalog:")
# Format the result in Nexus Variable format
return new_limits_df.copy(), self.format_result(new_limits_df)
def preprocess_data(self, base_limits: dict) -> pd.DataFrame:
"""Initialize dataframes with base values before they can be computed
Args:
base_limits: Dict that contains base limits and parameters, extracted from json
file
Returns:
df_base_limits: DataFrame with base_limits and parameters
cumulative_statistics: DataFrame with base columns and values to be used in
compute
"""
self.logger.info("=>Beginning of Init")
df_base_limits = pd.DataFrame.from_dict(base_limits, orient="index")
df_base_limits["TestId"] = df_base_limits.index.astype(int)
df_base_limits.reset_index(inplace=True, drop=True)
# Pick only columns of interest
cumulative_statistics = df_base_limits[
["TestId", "PassRangeUsl", "PassRangeLsl", "DPAT_Sigma"]
].copy()
# Set 0 to base columns
cumulative_statistics["nbr_executions"] = 0
cumulative_statistics["sum_of_squares"] = 0
cumulative_statistics["sum"] = 0
self.logger.info("=>End of Init")
return df_base_limits, cumulative_statistics
workdir/oneapi.py:
By using OneAPI, this code performs the following functions:Retrieves test data from the Host Controller and sends it to the DPAT algorithm.
Receives the DPAT results from the algorithm and sends them back to the Host Controller.
Click to expand!
from liboneAPI import Interface
from liboneAPI import AppInfo
from sample import SampleMonitor
from sample import sendCommand
import signal
import sys
import pandas as pd
from AdvantestLogging import logger
def send_command(result_str, command):
# name = command;
# param = "DriverEvent LotStart"
# sendCommand(name, param)
name = command
param = "DriverEvent LotStart"
sendCommand(name, param)
name = command
param = "Config Enabled=1 Timeout=10"
sendCommand(name, param)
name = command
param = "Set " + result_str
sendCommand(name, param)
logger.info(result_str)
class OneAPI:
def __init__(self, callback_fn, callback_args):
self.callback_args = callback_args
self.get_suite_config(callback_args["config_path"])
self.monitor = SampleMonitor(
callback_fn=callback_fn, callback_args=self.callback_args
)
def get_suite_config(self, config_path): # conf/test_suites.ini
test_suites = []
with open(config_path) as f:
for line in f:
li = line.strip()
if not li.startswith("#"):
test_suites.append(li.split(","))
self.callback_args["test_suites"] = pd.DataFrame(
test_suites, columns=["testNumber", "testName"]
)
def start(
self,
):
signal.signal(signal.SIGINT, quit)
logger.info("Press 'Ctrl + C' to exit")
me = AppInfo()
me.name = "sample"
me.vendor = "adv"
me.version = "2.1.0"
Interface.registerMonitor(self.monitor)
NexusDataEnabled = True # whether to enable Nexus Data Streaming and Control
TPServiceEnabled = (
True # whether to enable TPService for communication with NexusTPI
)
res = Interface.connect(me, NexusDataEnabled, TPServiceEnabled)
if res != 0:
logger.info(f"Connect fail. code = {res}")
sys.exit()
logger.info("Connect succeed.")
signal.signal(signal.SIGINT, quit)
while True:
signal.pause()
def quit(
self,
):
sys.exit()
Build the docker image “adv-dpat” and upload it to ACS Container Hub.
Login to the ACS Container Hub in advance.
sudo docker login registry.advantest.com --username Your_Email --password Your_ContainerHub_Secret
Build image and push it to the Container Hub
cd ~/apps/application-dpat-v3.1.0 sudo docker build --tag registry.advantest.com/adv-dpat/adv-dpat-v1:usermodel rd-app_dpat_py/. sudo docker push registry.advantest.com/adv-dpat/adv-dpat-v1:usermodel
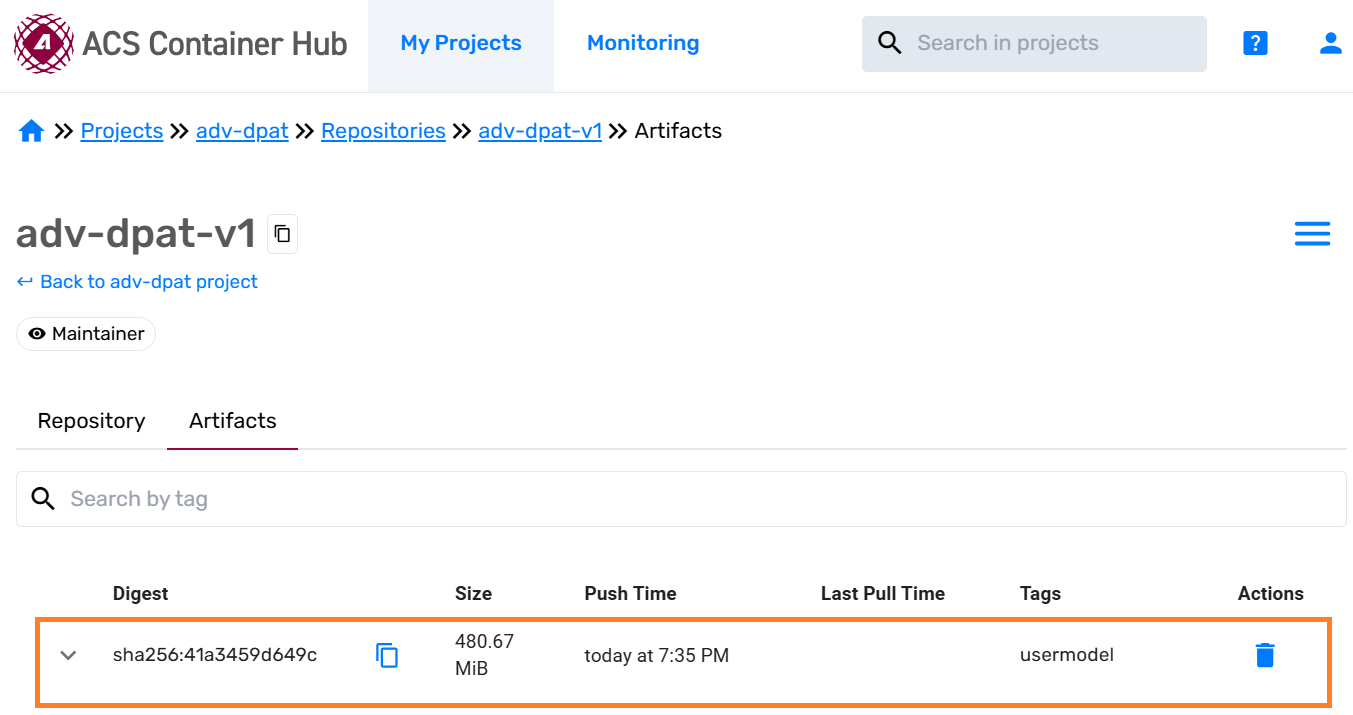
Confirm that the docker image has been uploaded to the Container Hub.
4. Configure acs_nexus system service#
Edit /opt/acs/nexus/conf/acs_nexus.ini file.
Make sure the Auto_Deploy option is false
[Auto_Deploy] Enabled=false
Make sure the Auto_Popup option is true
[GUI] Auto_Popup=true Auto_Close=true
Edit the image setting file (create it if it doesn’t exist) located at: /opt/acs/nexus/conf/images.json
The following content is for your reference, enter your own values for the address, user, and password fields.
{ "selector": { "device_name": "demo" }, "edge": { "address": "<Edge Private IP>", "registry": { "address": "registry.advantest.com", "user": "<Container Hub User Name>", "password": "<Docker Secret>" }, "containers": [ { "name": "dpat-app", "image": "adv-dpat/adv-dpat-v1:usermodel", "requirements": { "gpu": false, "mapped_ports": [ ] }, "environment": { "ONEAPI_CONTROL_ZMQ_IP": "<Host Controller Private IP>" } } ] } }
Finally, restart acs_nexus service to take effect
sudo systemctl restart acs_nexus
5. Start SmarTest.#
In the VNC GUI, open bash console. Navigate to the demo application directory, and excute the shell script to start SmarTest offline.
cd ~/apps/application-dpat-v3.1.0
./start_smt7.sh
Wait 1-2 minutes for Smartest to launch, in the popped up “Workspace Launcher” dialog, click “OK”.
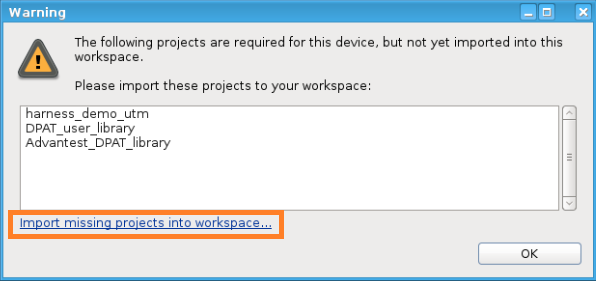
In the popped up warning dialog, click “Import missing projects into workspace…”
Click the “Finish” button in the next import dialog.
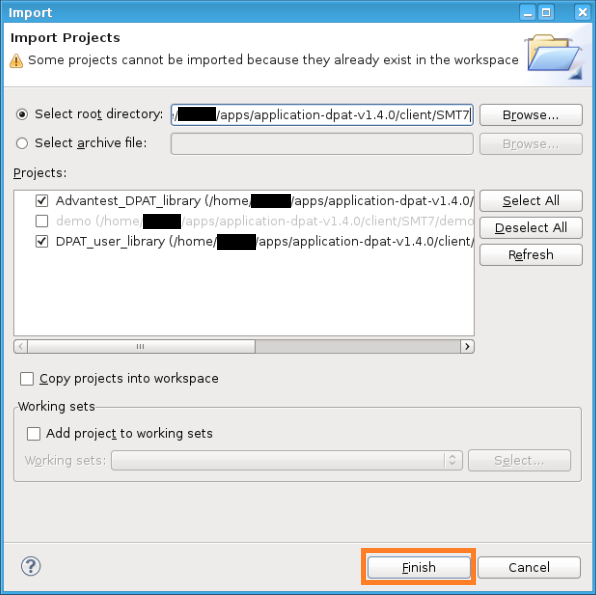
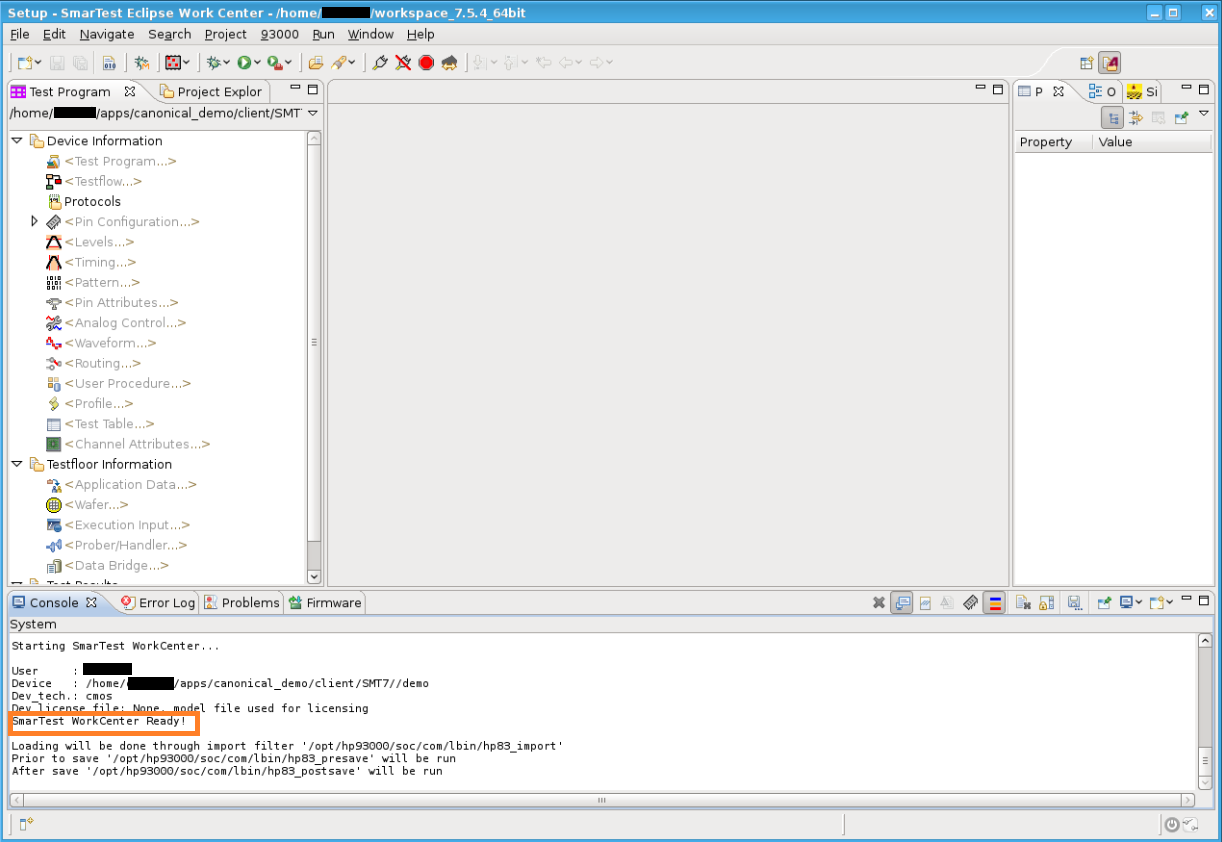
You are now in the SmarTest EWC workspace and should see “SmarTest WorkCenter Ready” in the console.
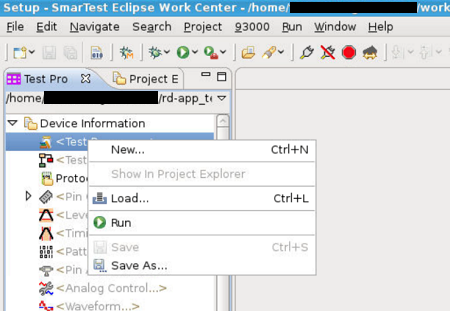
Load the test program “package_dpat”: right-click on the Testprogram entry in the “Test Program Explorer” (located in the left panel) and select “Load…”
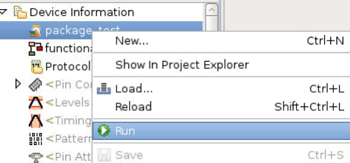
6. Start Edge container by running test program.#
Run the test program “package_dpat”: Change to the “Test Program” view, right-click on “package dpat” and click “Run”.
In the popped up “no_of_executions” dialog, input “1” then press “Enter” on keyboard.
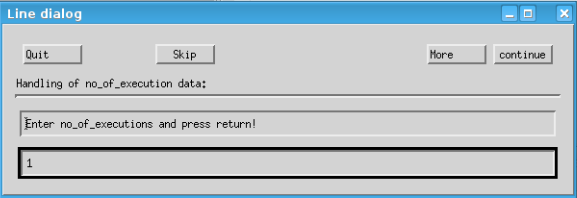
Confirm that the Container Hub app dpat-app is running on Edge Server
Download container status check tool
cd ~/apps curl http://10.44.5.139/edge_container_operation.py -O
Confirm the container app is running:
sudo python3 ~/apps/edge_container_operation.py edgesdk3.0.3-prod-v1 list <Edge Private IP>
You can find the app “dpat-app” is running in output
processing... Running containers: Name | Created dpat-app | 2025-08-10-11-45-32
You can also find the app “dpat-app” is running from Nexus GUI
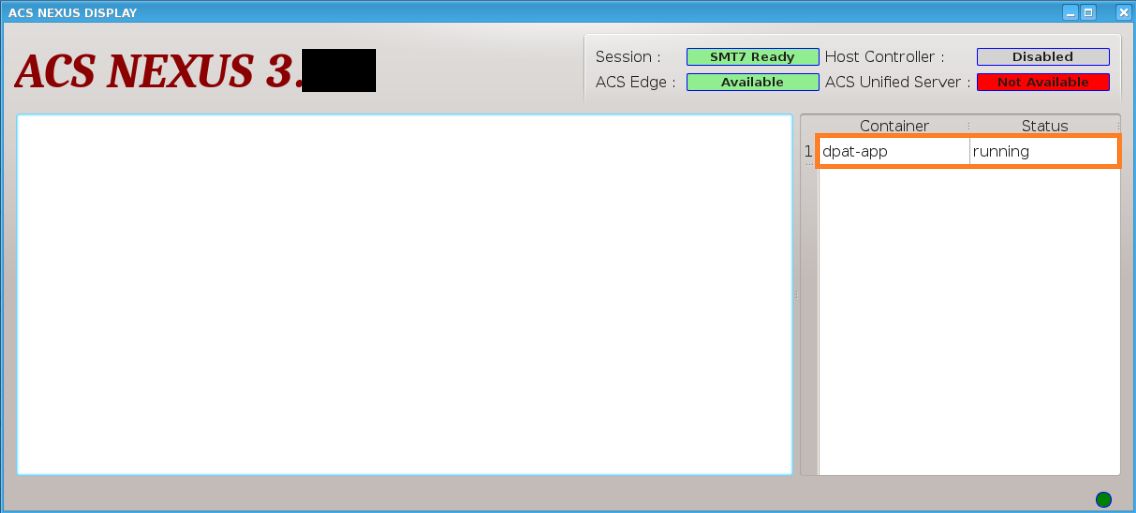
7. Stop container by quitting Smartest#
Click “X” to quit Smartest
When the Smartest ended, wait for 1~2 minutes, confirm the container app dpat-app is not running in Edge Server
sudo python3 ~/apps/edge_container_operation.py edgesdk3.0.3-prod-v1 list <Edge Private IP>
You can not find the app “dpat-app” is running in output
processing... Running containers: